04 | 穿越功耗墙,我们该从哪些方面提升“性能”?





讲述:徐文浩
时长15:10大小13.90M
上一讲,在讲 CPU 的性能时,我们提到了这样一个公式:
这么来看,如果要提升计算机的性能,我们可以从指令数、CPI 以及 CPU 主频这三个地方入手。要搞定指令数或者 CPI,乍一看都不太容易。于是,研发 CPU 的硬件工程师们,从 80 年代开始,就挑上了 CPU 这个“软柿子”。在 CPU 上多放一点晶体管,不断提升 CPU 的时钟频率,这样就能让 CPU 变得更快,程序的执行时间就会缩短。
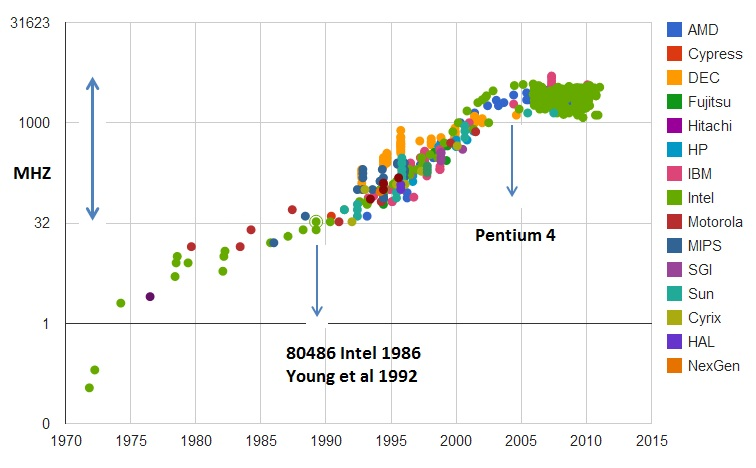
于是,从 1978 年 Intel 发布的 8086 CPU 开始,计算机的主频从 5MHz 开始,不断提升。1980 年代中期的 80386 能够跑到 40MHz,1989 年的 486 能够跑到 100MHz,直到 2000 年的奔腾 4 处理器,主频已经到达了 1.4GHz。而消费者也在这 20 年里养成了“看主频”买电脑的习惯。当时已经基本垄断了桌面 CPU 市场的 Intel 更是夸下了海口,表示奔腾 4 所使用的 CPU 结构可以做到 10GHz,颇有一点“大力出奇迹”的意思。
功耗:CPU 的“人体极限”
然而,计算机科学界从来不相信“大力出奇迹”。奔腾 4 的 CPU 主频从来没有达到过 10GHz,最终它的主频上限定格在 3.8GHz。这还不是最糟的,更糟糕的事情是,大家发现,奔腾 4 的主频虽然高,但是它的实际性能却配不上同样的主频。想要用在笔记本上的奔腾 4 2.4GHz 处理器,其性能只和基于奔腾 3 架构的奔腾 M 1.6GHz 处理器差不多。
于是,这一次的“大力出悲剧”,不仅让 Intel 的对手 AMD 获得了喘息之机,更是代表着“主频时代”的终结。后面几代 Intel CPU 主频不但没有上升,反而下降了。到如今,2019 年的最高配置 Intel i9 CPU,主频也只不过是 5GHz 而已。相较于 1978 年到 2000 年,这 20 年里 300 倍的主频提升,从 2000 年到现在的这 19 年,CPU 的主频大概提高了 3 倍。
奔腾 4 的主频为什么没能超过 3.8GHz 的障碍呢?答案就是功耗问题。什么是功耗问题呢?我们先看一个直观的例子。
一个 3.8GHz 的奔腾 4 处理器,满载功率是 130 瓦。这个 130 瓦是什么概念呢?机场允许带上飞机的充电宝的容量上限是 100 瓦时。如果我们把这个 CPU 安在手机里面,不考虑屏幕内存之类的耗电,这个 CPU 满载运行 45 分钟,充电宝里面就没电了。而 iPhone X 使用 ARM 架构的 CPU,功率则只有 4.5 瓦左右。
我们的 CPU,一般都被叫作超大规模集成电路(Very-Large-Scale Integration,VLSI)。这些电路,实际上都是一个个晶体管组合而成的。CPU 在计算,其实就是让晶体管里面的“开关”不断地去“打开”和“关闭”,来组合完成各种运算和功能。
想要计算得快,一方面,我们要在 CPU 里,同样的面积里面,多放一些晶体管,也就是增加密度;另一方面,我们要让晶体管“打开”和“关闭”得更快一点,也就是提升主频。而这两者,都会增加功耗,带来耗电和散热的问题。
这么说可能还是有点抽象,我还是给你举一个例子。你可以把一个计算机 CPU 想象成一个巨大的工厂,里面有很多工人,相当于 CPU 上面的晶体管,互相之间协同工作。
为了工作得快一点,我们要在工厂里多塞一点人。你可能会问,为什么不把工厂造得大一点呢?这是因为,人和人之间如果离得远了,互相之间走过去需要花的时间就会变长,这也会导致性能下降。这就好像如果 CPU 的面积大,晶体管之间的距离变大,电信号传输的时间就会变长,运算速度自然就慢了。
除了多塞一点人,我们还希望每个人的动作都快一点,这样同样的时间里就可以多干一点活儿了。这就相当于提升 CPU 主频,但是动作快,每个人就要出汗散热。要是太热了,对工厂里面的人来说会中暑生病,对 CPU 来说就会崩溃出错。
我们会在 CPU 上面抹硅脂、装风扇,乃至用上水冷或者其他更好的散热设备,就好像在工厂里面装风扇、空调,发冷饮一样。但是同样的空间下,装上风扇空调能够带来的散热效果也是有极限的。
因此,在 CPU 里面,能够放下的晶体管数量和晶体管的“开关”频率也都是有限的。一个 CPU 的功率,可以用这样一个公式来表示:
那么,为了要提升性能,我们需要不断地增加晶体管数量。同样的面积下,我们想要多放一点晶体管,就要把晶体管造得小一点。这个就是平时我们所说的提升“制程”。从 28nm 到 7nm,相当于晶体管本身变成了原来的 1/4 大小。这个就相当于我们在工厂里,同样的活儿,我们要找瘦小一点的工人,这样一个工厂里面就可以多一些人。我们还要提升主频,让开关的频率变快,也就是要找手脚更快的工人。

但是,功耗增加太多,就会导致 CPU 散热跟不上,这时,我们就需要降低电压。这里有一点非常关键,在整个功耗的公式里面,功耗和电压的平方是成正比的。这意味着电压下降到原来的 1/5,整个的功耗会变成原来的 1/25。
事实上,从 5MHz 主频的 8086 到 5GHz 主频的 Intel i9,CPU 的电压已经从 5V 左右下降到了 1V 左右。这也是为什么我们 CPU 的主频提升了 1000 倍,但是功耗只增长了 40 倍。比如说,我写这篇文章用的是 Surface Go,在这样的轻薄笔记本上,微软就是选择了把电压下降到 0.25V 的低电压 CPU,使得笔记本能有更长的续航时间。
并行优化,理解阿姆达尔定律
虽然制程的优化和电压的下降,在过去的 20 年里,让我们的 CPU 性能有所提升。但是从上世纪九十年代到本世纪初,软件工程师们所用的“面向摩尔定律编程”的套路越来越用不下去了。“写程序不考虑性能,等明年 CPU 性能提升一倍,到时候性能自然就不成问题了”,这种想法已经不可行了。
于是,从奔腾 4 开始,Intel 意识到通过提升主频比较“难”去实现性能提升,边开始推出 Core Duo 这样的多核 CPU,通过提升“吞吐率”而不是“响应时间”,来达到目的。
提升响应时间,就好比提升你用的交通工具的速度,比如原本你是开汽车,现在变成了火车乃至飞机。本来开车从上海到北京要 20 个小时,换成飞机就只要 2 个小时了,但是,在此之上,再想要提升速度就不太容易了。我们的 CPU 在奔腾 4 的年代,就好比已经到了飞机这个速度极限。
那你可能要问了,接下来该怎么办呢?相比于给飞机提速,工程师们又想到了新的办法,可以一次同时开 2 架、4 架乃至 8 架飞机,这就好像我们现在用的 2 核、4 核,乃至 8 核的 CPU。
虽然从上海到北京的时间没有变,但是一次飞 8 架飞机能够运的东西自然就变多了,也就是所谓的“吞吐率”变大了。所以,不管你有没有需要,现在 CPU 的性能就是提升了 2 倍乃至 8 倍、16 倍。这也是一个最常见的提升性能的方式,通过并行提高性能。
这个思想在很多地方都可以使用。举个例子,我们做机器学习程序的时候,需要计算向量的点积,比如向量 和向量 ,
。这些式子由 16 个乘法和 1 个连加组成。如果你自己一个人用笔来算的话,需要一步一步算 16 次乘法和 15 次加法。如果这个时候我们把这个人物分配给 4 个人,同时去算 , , , 这样四个部分的结果,再由一个人进行汇总,需要的时间就会缩短。

但是,并不是所有问题,都可以通过并行提高性能来解决。如果想要使用这种思想,需要满足这样几个条件。
第一,需要进行的计算,本身可以分解成几个可以并行的任务。好比上面的乘法和加法计算,几个人可以同时进行,不会影响最后的结果。
第二,需要能够分解好问题,并确保几个人的结果能够汇总到一起。
第三,在“汇总”这个阶段,是没有办法并行进行的,还是得顺序执行,一步一步来。
这就引出了我们在进行性能优化中,常常用到的一个经验定律,阿姆达尔定律(Amdahl’s Law)。这个定律说的就是,对于一个程序进行优化之后,处理器并行运算之后效率提升的情况。具体可以用这样一个公式来表示:
在刚刚的向量点积例子里,4 个人同时计算向量的一小段点积,就是通过并行提高了这部分的计算性能。但是,这 4 个人的计算结果,最终还是要在一个人那里进行汇总相加。这部分汇总相加的时间,是不能通过并行来优化的,也就是上面的公式里面不受影响的执行时间这一部分。
比如上面的各个向量的一小段的点积,需要 100ns,加法需要 20ns,总共需要 120ns。这里通过并行 4 个 CPU 有了 4 倍的加速度。那么最终优化后,就有了 100/4+20=45ns。即使我们增加更多的并行度来提供加速倍数,比如有 100 个 CPU,整个时间也需要 100/100+20=21ns。

总结延伸
我们可以看到,无论是简单地通过提升主频,还是增加更多的 CPU 核心数量,通过并行来提升性能,都会遇到相应的瓶颈。仅仅简单地通过“堆硬件”的方式,在今天已经不能很好地满足我们对于程序性能的期望了。于是,工程师们需要从其他方面开始下功夫了。
在“摩尔定律”和“并行计算”之外,在整个计算机组成层面,还有这样几个原则性的性能提升方法。
1.加速大概率事件。最典型的就是,过去几年流行的深度学习,整个计算过程中,99% 都是向量和矩阵计算,于是,工程师们通过用 GPU 替代 CPU,大幅度提升了深度学习的模型训练过程。本来一个 CPU 需要跑几小时甚至几天的程序,GPU 只需要几分钟就好了。Google 更是不满足于 GPU 的性能,进一步地推出了 TPU。后面的文章,我也会为你讲解 GPU 和 TPU 的基本构造和原理。
2.通过流水线提高性能。现代的工厂里的生产线叫“流水线”。我们可以把装配 iPhone 这样的任务拆分成一个个细分的任务,让每个人都只需要处理一道工序,最大化整个工厂的生产效率。类似的,我们的 CPU 其实就是一个“运算工厂”。我们把 CPU 指令执行的过程进行拆分,细化运行,也是现代 CPU 在主频没有办法提升那么多的情况下,性能仍然可以得到提升的重要原因之一。我们在后面也会讲到,现代 CPU 里是如何通过流水线来提升性能的,以及反面的,过长的流水线会带来什么新的功耗和效率上的负面影响。
3.通过预测提高性能。通过预先猜测下一步该干什么,而不是等上一步运行的结果,提前进行运算,也是让程序跑得更快一点的办法。典型的例子就是在一个循环访问数组的时候,凭经验,你也会猜到下一步我们会访问数组的下一项。后面要讲的“分支和冒险”、“局部性原理”这些 CPU 和存储系统设计方法,其实都是在利用我们对于未来的“预测”,提前进行相应的操作,来提升我们的程序性能。
好了,到这里,我们讲完了计算机组成原理这门课的“前情提要”。一方面,整个组成乃至体系结构,都是基于冯·诺依曼架构组成的软硬件一体的解决方案。另一方面,你需要明白的就是,这里面的方方面面的设计和考虑,除了体系结构层面的抽象和通用性之外,核心需要考虑的是“性能”问题。
接下来,我们就要开始深入组成原理,从一个程序的运行讲起,开始我们的“机器指令”之旅。
补充阅读
如果你学有余力,关于本节内容,推荐你阅读下面两本书的对应章节,深入研读。
1.《计算机组成与设计:软 / 硬件接口》(第 5 版)的 1.7 和 1.10 节,也简单介绍了功耗墙和阿姆达尔定律,你可以拿来细细阅读。
2. 如果你想对阿姆达尔定律有个更细致的了解,《深入理解计算机系统》(第 3 版)的 1.9 节不容错过。
课后思考
我在这一讲里面,介绍了三种常见的性能提升思路,分别是,加速大概率事件、通过流水线提高性能和通过预测提高性能。请你想一下,除了在硬件和指令集的设计层面之外,你在软件开发层面,有用到过类似的思路来解决性能问题吗?
欢迎你在留言区写下你曾遇到的问题,和大家一起分享、探讨。你也可以把今天的文章分享给你朋友,和他一起学习和进步。

精选留言(51)
- pyhhou2019-05-01 14对于思考题:
* 加速大概率事件
通常我们使用 big-O 去表示一个算法的好坏,我们优化一个算法也是基于 big-O,但是 big-O 其实是一个近似值,就好比一个算法时间复杂度是 O(n^2) + O(n),这里的 O(n^2) 是占大比重的,特别是当 n 很大的时候,通常我们会忽略掉 O(n),着手优化 O(n^2) 的部分
* 通过流水线提高性能
能够想到的是任务分解,把一个大的任务分解成好多个小任务,一般来说,分的越细,小任务就会越简单,整个框架、思路也会变得更加清晰
* 通过预测提高性能
常常在计算近似值的时候,例如计算圆周率,我们可以根据条件预设立一个精确率,高过这个精确率就会停止计算,防止无穷无尽的一直计算下去;另外就是深度优先搜索算法里面的 “剪枝策略”,防止没有必要的分支搜索,这会大幅度提升算法效率展开作者回复: 👍算法的例子举得很好,剪枝策略的例子也很好。
不过流水线和圆周率的例子不太好,可以再想想。 - 活的潇洒2019-05-01 12通读三遍全文,花了3个多小时做了笔记链接如下:
https://www.cnblogs.com/luoahong/p/10800379.html作者回复: 👍感谢分享给大家
 须臾即2019-05-01 7有两个问题没想明白:
须臾即2019-05-01 7有两个问题没想明白:
1.增加晶体管怎么提高运算速度?
提高主频好理解,计算的频繁一些,增加晶体管是干了什么,增加计算单元么,或者说是增加流水线控制单元。
2.cpu的电压是受了什么因素限制的?
既然电压低功耗低,那么各厂商应该都想把电压做的越低越好,现实是不容易办到,是哪些因素限制的?展开作者回复: 须臾即他9同学你好
增加晶体管可以增加硬件能够支持的指令数量,增加数字通路的位数,以及利用好电路天然的并行性,从硬件层面更快地实现特定的指令,所以增加晶体管也是常见的提升cpu性能的一种手段。
电压的问题在于两个,一个是电压太低就会导致电路无法联通,因为不管用什么作为电路材料,都是有电阻的,所以没有办法无限制降低电压,另外一个是对于工艺的要求也变高了,成本也更贵啊。- 大熊2019-05-07 5重新学习后,我又来了……
1. 加大概率事件:
缓存机制,提高平均概率下的性能;
运行时编译热点代码的机制;
Spring框架使用的单例模式(个人还不确定);
2. 通过流水线提高性能:
工作中可以尝试把一个大规模的SQL分成几个规模适当的小SQL进行执行;
并发编程;
3. 通过预测提高性能:
以前有的软件安装的时候,有一秒就安装好的感觉,之前我就在想,是不是我选择完安装路径之后,就已经开始有预安装的操作了;
使用chrome在打开几个tab页的情况下,直接关闭浏览器,再次打开浏览器之前强制关闭的tab页直接默认打开的操作(不知道是否属于预测,预测我还是需要这几个页面);
在自己练习的博客中,多张图片在上传的时候,先让图片及时上传并处于“预删除”状态,待点击提交之后,才让现有的图片变成保存的状态。
热点数据、常用的固定数据,可以先保存在redis等缓存中,等到需要的时候先从缓存中获得,如果获取失败再去查询数据库展开作者回复: 👍你学得非常认真努力,给大家做了一个好榜样。
 JiangPQ2019-05-11 2关于这一课的组织结构上一点建议:
JiangPQ2019-05-11 2关于这一课的组织结构上一点建议:
1. 在电路设计上,并行和流水线通常是相互配合同时存在的,但是老师在讲述时将这两点分离了,我个人感觉会让不懂电路设计的读者会产生困惑。
2. 切流水线的意思是在电路的关键路径中的特定位置处插入寄存器,用空间换时间,使得切分后的关键路径的每一段具有更短的执行时间,但在总体上看单条指令的总体运行时间并不会减少。在切流水线后,电路可以使用更高的时钟频率,所以其主要目的还是在于提高主频。在文中“也是现代 CPU 在主频没有办法提升那么多的情况下,性能仍然可以得到提升的重要原因之一”的表达似乎不是那么精确。
我的理解可能也有不准确的地方,还麻烦老师指正。
前两天搞毕设,天天就是并行流水的捣腾,做硬件真的使人头秃...展开 arvin2019-05-11 2老师您好,两个问题没能理解。1:程序如何自动执行的。2,二进制概念的0和1计算机又是如何对应到高电压低电压的。
arvin2019-05-11 2老师您好,两个问题没能理解。1:程序如何自动执行的。2,二进制概念的0和1计算机又是如何对应到高电压低电压的。作者回复: arvin你好,第一个问题我们会在讲解cpu的第一部分详细讲解。核心是一个时钟信号和一个自动计数器。
第二个问题我们在后面讲电路的时候会介绍,可以认为就是电路的开闭。 古夜2019-05-06 2打孔编程那里说得太简略了,而且,看题目的意思似乎是要从打孔编程讲起,然后一步步来说计算机怎么理解打孔,如何编译,如何运行的吧,感觉文章里写反了,是不是五一有点仓促了展开
古夜2019-05-06 2打孔编程那里说得太简略了,而且,看题目的意思似乎是要从打孔编程讲起,然后一步步来说计算机怎么理解打孔,如何编译,如何运行的吧,感觉文章里写反了,是不是五一有点仓促了展开作者回复: 古夜同学你好,谢谢反馈。对于计算机如何编译运行,是一个挺复杂的话题了,恐怕一讲之内讲不清楚。这一讲的主要目标,还是让大家明白指令和机器码是怎么回事儿。
关于计算机如何阅读指令运行的整理流程,会在17讲讲解CPU部分的时候做深入的剖析。- KR®2019-05-02 2对于我这种小白来说,能啃完这些知识点要感谢初中物理老师为我打下的物理基础 哈哈,
徐老师的讲解也太清晰了吧!!!
能看懂跟得上节奏的感觉真好~
还要感谢高阶的同学们,我没有开发经验,看文章时遇到一些专业名词会一脸懵, 好在高阶的同学会在答疑区提问互动, 看你们的提问和回答我都会有收获!展开作者回复: 👍谢谢支持,要坚持和大家多交流
 Seventy、2019-05-11 1老师您好,有个疑问,上节课我们讲过“程序运行CPU执行时间 = 指令数 * CPI * 时钟周期时间(Clock Cycle Time)”,而这节中提到增加晶体管数量会提升CPU性能,请问"晶体管数量"与上面的公式有什么关系呢? 还是说晶体管数量会影响上面公式的三个部分中的哪一部分?? 盼老师答复。
Seventy、2019-05-11 1老师您好,有个疑问,上节课我们讲过“程序运行CPU执行时间 = 指令数 * CPI * 时钟周期时间(Clock Cycle Time)”,而这节中提到增加晶体管数量会提升CPU性能,请问"晶体管数量"与上面的公式有什么关系呢? 还是说晶体管数量会影响上面公式的三个部分中的哪一部分?? 盼老师答复。作者回复: 增加晶体管数量,其实是通过提供更复杂的电路支持更多的“指令”。也就会减少运行同样程序需要的指令数。
打个比方,比如我们最简单的电路可以只有加法功能,没有乘法功能。乘法都变成很多个加法指令,那么实现一个乘法需要的指令数就比较多。但是如果我们增加晶体管在电路层面就实现了这个,那么需要的指令数就变少了,执行时间也可以缩短。- 不记年2019-05-07 1加速大概率时间,优化工程中的使用次数最多的算法展开
- ginger2019-05-23哦对了,之前就听说,其实在淘宝买东西时候,页面显示购买成功了,其实并不是真正的成功过了,后台还有很多数据流程没有跑完,那么我觉得,这个一定是属于预测的,在我的提交动作触发之前,代码需要先确定我是一定鞥呢成功的,那么提交动作一旦触发,页面就会告诉我,成功了,但是实际上,还有很多事情在有条不紊的执行着.展开
作者回复: 这个淘宝买东西和预测的关系不大,最多算是异步计算。
- ginger2019-05-23算法小白想到的预测例子:
通过预测集合大小,来定义集合初始化容量.哈哈
统计学中肯定有一些预测分析算法可以用到代码思路中.
分支算不算就是一种预测.
等以后学习了些法,我要再举一些例子出来.展开作者回复: 👍第一个例子不错
- ginger2019-05-23a:
1.主频瓶颈:
虽然晶体管数量能够增加主频,但是晶体管越小,主频应该也越难以控制
再加之两者都是功耗的乘法计算因子,所以晶体管几乎不能继续优化来提升主频.
2.功耗瓶颈:
功耗太大必然带来耗电量,温度,噪音,稳定性等很多方面的挑战,因此功耗是需要约底约好的
所以这里1.2两点已经矛盾,而很多计算机厂商,都选择了降低电压来降低功耗.
b:
cpu工程师们,一开始疯狂提升主频,来达到cpu性能优化,当晶体管和通信面积已经不能满足主频优化的时候,工程师们选择为cpu搭建集群,同时计算了集群的优化瓶颈(这里我简单理解为无限接近不受影响的时间),然后工程师们坚持理想,目光最后瞄准了电压,毕竟功耗和电压的平方是正比的,电压的优化带来的收益相较于其他更加直观.也就出现了电压降低20被的微软超极本.
c:
看来GPU并不是CPU那样的一层层封装简单算数运算的(这个说法应该不准确.)那么计算机继续发展,会不会是cpu,gpu,tpu更过的pu来处理多种不同的算数方式.
另一个疑问是,GPU最底层,是数字电路来处理简单运算吗,如果是,那么GPU相比CPU在计算向量,矩阵时候的优势是那些,会是像人工分析矩阵那样子转换成别的算法计算吗.
d:
流水线可不可以理解为将任务原子化,像我们代码的的耦合似的.
e:
预测提高性能,可不可以先简单理解为:我的一行代码执行之初,我就在脑海里边去想了如果结果是1,我要干啥,如果结果是2我要干啥,比如检查bug时候,一个命令下去,我再结果出来之前想好,哪种结果对应的bug位置在哪里种种.
f:
作为一个初级开发人员,我在软件开发中思考过的性能包括和数据库交互时候,我是选择一次交互拿来了数据之后,让服务器cpu去处理,还是我设计好了交互次数,每次取不同的数据,再交给cpu处理;
或者和数据库交互时候,我是让交互次数多一点还是让IO处理数据多一点.
如果现在让我基于课程中的点来想,我觉得,缓存是必须优先考虑的(加速大概率事件),还有连接池应该也属于这里;有些时候低耦合也是性能提升的一个方式,处理一些数据时候,尽量少的让多于的数据参与进来;预测来提升性能嘛,我觉得将数据,在数据库层面,用宽表存储,应该也能算这一点吧...
忘指正,嘻嘻.展开 - ginger2019-05-23终于理解为什么很多笔记本会出低压版本了,原来是电压的平方和功耗是正比的,也就是电压的降低对于功耗来说,降低效益最好,还记得之前选笔记本时候,我发现几乎所有的超薄本,都是低压版本的.大致是因为超薄设计导致不能使用很"给力"的散热系统吧,所以通过低压来降低功耗,尽管低压也会让CPU性能有所下降.展开
作者回复: 👍
 莫问流年2019-05-201.加速大概率事件
莫问流年2019-05-201.加速大概率事件
各种缓存(内存缓存、CDN缓存)
2.流水线
并发编程、异步编程
音视频播放器边播放边缓冲
3.预测
小说的下一页预加载
电商大促的CDN预热展开作者回复: 几个例子举得都很好!而且和实践应用结合得也很好!
 Yoooooo2019-05-20常见的思路比如多线程增加并发量,上线分布式计算,操作分离增加计算速度。
Yoooooo2019-05-20常见的思路比如多线程增加并发量,上线分布式计算,操作分离增加计算速度。 shark2019-05-19总结:
shark2019-05-19总结:
性能提升上,参照上节的公式,首先还是提高主频,方法考虑提高晶体管密度,有缩小制程和提高电路性能,但这种硬件方式都会碰到功耗墙,一是晶体管所需的电压必须保证,二是密度大了功耗自然大了,我其实听我们老师说开始考虑3D电路了。之后解决方案是并行处理多核提高吞吐率。
实际上现阶段的发展考虑的是以下三中,一是大概率计算的优化,感觉类似是简化cpi;二是预测结果,三是并行展开作者回复: 是的,比如最近比较热的RISC-V其实就是想让大家能根据自己的实际应用的Load在开源的指令集上去设计自己的CPU
 风翱2019-05-13开发中使用到的缓存,和加速大概率事件思路有点类似;采用的多线程技术,和通过流水线提高性能,也是有异曲同工的地方。
风翱2019-05-13开发中使用到的缓存,和加速大概率事件思路有点类似;采用的多线程技术,和通过流水线提高性能,也是有异曲同工的地方。作者回复: 👍
- 静静的拼搏2019-05-12LongAdder是java1.8juc包提供的计数器工具类,将计数分为多个cell分开计算,最后将结果汇总sum,类似cpu的流水线工作机制,以上为流水线例子说明展开
- 萝卜祥子2019-05-11对于并行和并发的理解:
并发是指:cpu具有接受处理多个任务的能力,是可以在任务之间进行切换,并且可以切换到原先的任务。
并行是指:利用并发的这种特性,实现同时执行不同任务的能力。
不知道这样理解是不是正确,老师能解答一下吗?还有网上的资料说并发是以相同时间间隔处理,这个是指任务调度中的时间片?展开 - 萝卜祥子2019-05-10在遍历二维数组的时候是按照行优先还是列优先两者就有很大不同,前者能够更高的符合空间局部性原理
作者回复: 👍我们在存储器的高速缓存部分会专门讲一下这个。
- 不记年2019-05-10作者大大,关于协程是流水线的问题其实我是这样想的,流水线的目的就是减少cpu空闲的电路, 尽量让cpu每一部分都工作起来。而协程的也是减少cpu空闲的时间,更好的利用cpu,感觉两者有异曲同工之妙就写下来啦展开
作者回复: 赞思路,不过我觉得还是不太一样的。它更像“抢跑”而不像防止浪费和空闲。
- 静静的拼搏2019-05-08加速大概率事件:在程序中遇到的是使用缓存,减少热点数据的查询时间
流水线:java程序juc包提供的LongAdder工具类采用了这种思路,提高运算效率
预测:目前还没有遇到过作者回复: 静静的拼搏同学你好,关于LongAdder可以更具体地和大家分享一下吗?
 李心宇🦉2019-05-08预测 冒险: 热点内容加缓存展开
李心宇🦉2019-05-08预测 冒险: 热点内容加缓存展开 Phil2019-05-07在循环中不发生变化的变量赋值可以提到循环外面进行;还有在集合类中存储对象时不直接存储对象,而是存储类的路径,需要时通过反射动态加载创建对象展开
Phil2019-05-07在循环中不发生变化的变量赋值可以提到循环外面进行;还有在集合类中存储对象时不直接存储对象,而是存储类的路径,需要时通过反射动态加载创建对象展开- 不记年2019-05-07加速大概率事件 优化工程中使用次数最多的算法
流水线 协程
预测 剪枝展开作者回复: 👍 关于协程是流水线能具体解释一下么?我没有太明白。
- 大熊2019-05-06又再次仔细阅读专栏和资料,确实是我一开始的理解过于粗浅,只停留在了字面意思的感觉。整理一下我重新做这个思考题。
 Only now2019-05-05概率:
Only now2019-05-05概率:
JIT 运行时编译, 可以通过profiling数据, 将小概率甚至死代码排除, 只运行有效部分。
流水线:
这个不就是缓存系统典型的消费者生产者模型么? 日志系统表现的最明显, 生产者将日志塞入日志缓存, 日志线程则负责从日志缓存里取出数据记录到磁盘, sync进程则负责将关键日志推送到集中存储。
预测:
缓存热点数据, 因为大部分的访问都是访问热点数据, 所以, 我可以预测下一次访存大概率就是在热点缓存里, 先去热点缓存中查找数据, 若不存在,再去落地库进行索引
展开作者回复: 👍概率和预测说得很好
不过CPU的流水线还是比较特殊的,和我们一般理解的流水线的方式其实还是有些差异,可以在后面特别深入关注一下流水线的部分。 知非2019-05-05加速大概率事件:
知非2019-05-05加速大概率事件:
- 缓存
流水线:
- 开发过程中功能分解
预测:
- 剪纸
- 浏览器预加载展开作者回复: 👍说得不错,不过“剪纸”是什么能具体说说么?
- 大熊2019-05-031. 加大概率事件:
换在软件开发中,使用更好的数据结构和更符合事宜的算法,来优化时间、空间复杂度;
2. 通过流水线提高性能:
开发中的分治思想;
3. 通过预测提高性能:
类似树的“剪枝”,去除不必要的多余的计算;我觉得前端做的各种数据的check,应该也属于一种预测吧;共通方法的抽取,提高代码的可复用性。展开作者回复: 大熊同学你好,
加速大概率事件的例子可以找一些更具体的
流水线的确是进行了分治,不过还有很重要的一点是前后的步骤在多个指令的情况下是并行的
剪枝也的确是预测思想的一种,但是数据check不能称之为“预测”了。预测也不是为了提高代码的复用性。
可以看看其他同学的答案一起参考一下。  庄小P2019-05-03老师你说低压的通常主频只有标压的2/3,那是为什么要这样呢?按理说,低压时候功耗更低了。同等功耗下,低压的主频不应该高于标压的主频嘛?
庄小P2019-05-03老师你说低压的通常主频只有标压的2/3,那是为什么要这样呢?按理说,低压时候功耗更低了。同等功耗下,低压的主频不应该高于标压的主频嘛?
另外一个问题是,上面的计算向量的点积时候,我能不能通过多加两个CPU来计算求和,然后最后再进行汇总,这样是不是还能提高性能呢??展开作者回复: 庄小P同学你好,
低压和低主频都是为了减少能耗。比如Surface Go的电池很小,机器的尺寸也很小。如果用上高主频,性能更好了,但是耗电并没有下来。
另外,低电压对于CPU的工艺有更高的要求,因为太低的电压可能导致电路都不能导通,要高主频一样对工艺有更高的要求。所以一般低压CPU都是通过和低主频配合,用在对于移动性和续航要求比较高的机器上。
向量计算是可以通过让加法也并行来优化的,不过真实的CPU里面其实是通过SIMD指令来优化向量计算的,我在后面也会讲到SIMD指令。 ...2019-05-03我觉得可以把显存给CPU用来提高展开
...2019-05-03我觉得可以把显存给CPU用来提高展开作者回复: 能说说具体为什么吗?
 沃野阡陌2019-05-02老师,什么是缓存?需要用程序去操作吗?和内存又有什么关系?展开
沃野阡陌2019-05-02老师,什么是缓存?需要用程序去操作吗?和内存又有什么关系?展开作者回复: 沃野阡陌同学你好,答案取决于你这里指的缓存是什么。抽象的缓存,比如我们可以用redis或者memcqched作为访问数据库的缓存。具象的有时候一般我们指cpu里内置的高速缓存,也就是l1到l3 cache。前者一般都是应用程序来操作,后者不需要程序来操作。
后者内置在cpu里,比内存还要快上10到100倍。在讲解存储器的部分我们会重点讲解高速缓存以及怎么利用高速缓存的性能来写程序。 Juexe2019-05-021. 加速大概率事件
Juexe2019-05-021. 加速大概率事件
可能如 Redis 缓存、CDN 内容分发网络、游戏开发中常用的对象池等
2. 通过流水线提高性能
可能如多线程开发、分布式系统、DDOS攻击等
3.通过预测提高性能
浏览器的一个功能:下一页自动预加载;
Web 开发中用到的一个 InstantClick.js 能够预加载 hover 的链接。
不过「加速大概率事件」和「通过预测提高性能」好像有些重合,分得不是很清楚?展开作者回复: 👍加速大概率事件,通常指在我们确定了概率的情况下做出性能优化。而预测很多时候并不要求是大概率事件,只要平均情况下比不预测要明显好就够了。
- KR®2019-05-02提问, 这里说的预测是硬件cpu层面的预测吗?硬件是固定的,通过什么方式可以预测各种不同软件的下一步呢
作者回复: 计算机硬件里面有专门的分支预测电路,后面我们会有一讲专门讲到。
如果着急想要了解的话,也可以先看一下对应的wikipedia https://en.wikipedia.org/wiki/Branch_predictor - 活的潇洒2019-05-02对于思考题:
通过预测提高性能
3、浏览器缓存
4、redis缓存
通过流水线提高
1、最前段使用类似于F5的硬件设备设备
2、两台负载nginx负载均衡
5、微服务springcloud展开作者回复: 活得潇洒同学你好,
预测部分说的不错。
流水线部分能更详细地解释一下是怎么编程流水线的么? - 活的潇洒2019-05-01对于思考题:
1、最前段使用类似于F5的硬件设备设备
2、两台负载nginx负载均衡
3、浏览器缓存
4、消息队列
5、微服务springcloud展开作者回复: 能具体讲一下你觉得这些问题和哪个性能优化策略对上了么?
 魏宇靖2019-05-01我对大概率事件的理解是大规模(一系列)即将需要处理的事件,每个个体的概率不小,而且量极大,所以文中说把这些专门交给GPU(TPU)处理可以提高性能
魏宇靖2019-05-01我对大概率事件的理解是大规模(一系列)即将需要处理的事件,每个个体的概率不小,而且量极大,所以文中说把这些专门交给GPU(TPU)处理可以提高性能
不知道自己有没有理解偏作者回复: 魏宇靖同学你好,这里的大概率事件,就是指实际程序运行频繁发生的事件。比如机器学习里面大量要做矩阵向量运算,所以我们优化矩阵向量运算就能大幅度提高性能。而对于矩阵向量运算,gpu比cpu快很多,所以在这个场景下用gpu运算就比用cpu运算整体性能提升很多
 易儿易2019-05-01同样主频、核心情况下,低压cpu与标压cpu性能有区别吗?通过公式来看的话应该没有区别,但是经常听到有人讲低压cpu性能打不过标压,对吗?是什么原因呢?展开
易儿易2019-05-01同样主频、核心情况下,低压cpu与标压cpu性能有区别吗?通过公式来看的话应该没有区别,但是经常听到有人讲低压cpu性能打不过标压,对吗?是什么原因呢?展开作者回复: 性能的差异是因为主频就有差异,同样代号的intel cpu,低压的通常主频只有标压的2/3,比如i5-4200m的主频是2.5GHz到3.1GHz。而低压版本的i5-4200u就只有1.6GHz到2.5GHz。它们只是代号相同,主频并不一样
- Geek_fredW2019-05-01我也不明白“加速大概率事件”在文中具体含义。加速可以粗略意识到含义。为什么要提大概率?还是缓存命中?
作者回复: Geek_fredW同学你好,因为如果加速的是一个小概率事件,那么对于整体的性能提升就很有限。
缓存就是一个典型的情况,如果缓存的数据是很少被访问的,加速的就变成了一个小概率事件,那么缓存就并不能提升太多性能也就失去意义了






















{kind=link}