44 | Socket内核数据结构:如何成立特大项目合作部?





讲述:刘超
时长20:23大小18.67M
上一节我们讲了 Socket 在 TCP 和 UDP 场景下的调用流程。这一节,我们就沿着这个流程到内核里面一探究竟,看看在内核里面,都创建了哪些数据结构,做了哪些事情。
解析 socket 函数
我们从 Socket 系统调用开始。
这里面的代码比较容易看懂,Socket 系统调用会调用 sock_create 创建一个 struct socket 结构,然后通过 sock_map_fd 和文件描述符对应起来。
在创建 Socket 的时候,有三个参数。
一个是family,表示地址族。不是所有的 Socket 都要通过 IP 进行通信,还有其他的通信方式。例如,下面的定义中,domain sockets 就是通过本地文件进行通信的,不需要 IP 地址。只不过,通过 IP 地址只是最常用的模式,所以我们这里着重分析这种模式。
第二个参数是type,也即 Socket 的类型。类型是比较少的。
第三个参数是protocol,是协议。协议数目是比较多的,也就是说,多个协议会属于同一种类型。
常用的 Socket 类型有三种,分别是 SOCK_STREAM、SOCK_DGRAM 和 SOCK_RAW。
SOCK_STREAM 是面向数据流的,协议 IPPROTO_TCP 属于这种类型。SOCK_DGRAM 是面向数据报的,协议 IPPROTO_UDP 属于这种类型。如果在内核里面看的话,IPPROTO_ICMP 也属于这种类型。SOCK_RAW 是原始的 IP 包,IPPROTO_IP 属于这种类型。
这一节,我们重点看 SOCK_STREAM 类型和 IPPROTO_TCP 协议。
为了管理 family、type、protocol 这三个分类层次,内核会创建对应的数据结构。
接下来,我们打开 sock_create 函数看一下。它会调用 __sock_create。
这里先是分配了一个 struct socket 结构。接下来我们要用到 family 参数。这里有一个 net_families 数组,我们可以以 family 参数为下标,找到对应的 struct net_proto_family。
我们可以找到 net_families 的定义。每一个地址族在这个数组里面都有一项,里面的内容是 net_proto_family。每一种地址族都有自己的 net_proto_family,IP 地址族的 net_proto_family 定义如下,里面最重要的就是,create 函数指向 inet_create。
我们回到函数 __sock_create。接下来,在这里面,这个 inet_create 会被调用。
在 inet_create 中,我们先会看到一个循环 list_for_each_entry_rcu。在这里,第二个参数 type 开始起作用。因为循环查看的是 inetsw[sock->type]。
这里的 inetsw 也是一个数组,type 作为下标,里面的内容是 struct inet_protosw,是协议,也即 inetsw 数组对于每个类型有一项,这一项里面是属于这个类型的协议。
inetsw 数组是在系统初始化的时候初始化的,就像下面代码里面实现的一样。
首先,一个循环会将 inetsw 数组的每一项,都初始化为一个链表。咱们前面说了,一个 type 类型会包含多个 protocol,因而我们需要一个链表。接下来一个循环,是将 inetsw_array 注册到 inetsw 数组里面去。inetsw_array 的定义如下,这个数组里面的内容很重要,后面会用到它们。
我们回到 inet_create 的 list_for_each_entry_rcu 循环中。到这里就好理解了,这是在 inetsw 数组中,根据 type 找到属于这个类型的列表,然后依次比较列表中的 struct inet_protosw 的 protocol 是不是用户指定的 protocol;如果是,就得到了符合用户指定的 family->type->protocol 的 struct inet_protosw *answer 对象。
接下来,struct socket *sock 的 ops 成员变量,被赋值为 answer 的 ops。对于 TCP 来讲,就是 inet_stream_ops。后面任何用户对于这个 socket 的操作,都是通过 inet_stream_ops 进行的。
接下来,我们创建一个 struct sock *sk 对象。这里比较让人困惑。socket 和 sock 看起来几乎一样,容易让人混淆,这里需要说明一下,socket 是用于负责对上给用户提供接口,并且和文件系统关联。而 sock,负责向下对接内核网络协议栈。
在 sk_alloc 函数中,struct inet_protosw *answer 结构的 tcp_prot 赋值给了 struct sock *sk 的 sk_prot 成员。tcp_prot 的定义如下,里面定义了很多的函数,都是 sock 之下内核协议栈的动作。
在 inet_create 函数中,接下来创建一个 struct inet_sock 结构,这个结构一开始就是 struct sock,然后扩展了一些其他的信息,剩下的代码就填充这些信息。这一幕我们会经常看到,将一个结构放在另一个结构的开始位置,然后扩展一些成员,通过对于指针的强制类型转换,来访问这些成员。
socket 的创建至此结束。
解析 bind 函数
接下来,我们来看 bind。
在 bind 中,sockfd_lookup_light 会根据 fd 文件描述符,找到 struct socket 结构。然后将 sockaddr 从用户态拷贝到内核态,然后调用 struct socket 结构里面 ops 的 bind 函数。根据前面创建 socket 的时候的设定,调用的是 inet_stream_ops 的 bind 函数,也即调用 inet_bind。
bind 里面会调用 sk_prot 的 get_port 函数,也即 inet_csk_get_port 来检查端口是否冲突,是否可以绑定。如果允许,则会设置 struct inet_sock 的本方的地址 inet_saddr 和本方的端口 inet_sport,对方的地址 inet_daddr 和对方的端口 inet_dport 都初始化为 0。
bind 的逻辑相对比较简单,就到这里了。
解析 listen 函数
接下来我们来看 listen。
在 listen 中,我们还是通过 sockfd_lookup_light,根据 fd 文件描述符,找到 struct socket 结构。接着,我们调用 struct socket 结构里面 ops 的 listen 函数。根据前面创建 socket 的时候的设定,调用的是 inet_stream_ops 的 listen 函数,也即调用 inet_listen。
如果这个 socket 还不在 TCP_LISTEN 状态,会调用 inet_csk_listen_start 进入监听状态。
这里面建立了一个新的结构 inet_connection_sock,这个结构一开始是 struct inet_sock,inet_csk 其实做了一次强制类型转换,扩大了结构,看到了吧,又是这个套路。
struct inet_connection_sock 结构比较复杂。如果打开它,你能看到处于各种状态的队列,各种超时时间、拥塞控制等字眼。我们说 TCP 是面向连接的,就是客户端和服务端都是有一个结构维护连接的状态,就是指这个结构。我们这里先不详细分析里面的变量,因为太多了,后面我们遇到一个分析一个。
首先,我们遇到的是 icsk_accept_queue。它是干什么的呢?
在 TCP 的状态里面,有一个 listen 状态,当调用 listen 函数之后,就会进入这个状态,虽然我们写程序的时候,一般要等待服务端调用 accept 后,等待在哪里的时候,让客户端就发起连接。其实服务端一旦处于 listen 状态,不用 accept,客户端也能发起连接。其实 TCP 的状态中,没有一个是否被 accept 的状态,那 accept 函数的作用是什么呢?
在内核中,为每个 Socket 维护两个队列。一个是已经建立了连接的队列,这时候连接三次握手已经完毕,处于 established 状态;一个是还没有完全建立连接的队列,这个时候三次握手还没完成,处于 syn_rcvd 的状态。
服务端调用 accept 函数,其实是在第一个队列中拿出一个已经完成的连接进行处理。如果还没有完成就阻塞等待。这里的 icsk_accept_queue 就是第一个队列。
初始化完之后,将 TCP 的状态设置为 TCP_LISTEN,再次调用 get_port 判断端口是否冲突。
至此,listen 的逻辑就结束了。
解析 accept 函数
接下来,我们解析服务端调用 accept。
accept 函数的实现,印证了 socket 的原理中说的那样,原来的 socket 是监听 socket,这里我们会找到原来的 struct socket,并基于它去创建一个新的 newsock。这才是连接 socket。除此之外,我们还会创建一个新的 struct file 和 fd,并关联到 socket。
这里面还会调用 struct socket 的 sock->ops->accept,也即会调用 inet_stream_ops 的 accept 函数,也即 inet_accept。
inet_accept 会调用 struct sock 的 sk1->sk_prot->accept,也即 tcp_prot 的 accept 函数,inet_csk_accept 函数。
inet_csk_accept 的实现,印证了上面我们讲的两个队列的逻辑。如果 icsk_accept_queue 为空,则调用 inet_csk_wait_for_connect 进行等待;等待的时候,调用 schedule_timeout,让出 CPU,并且将进程状态设置为 TASK_INTERRUPTIBLE。
如果再次 CPU 醒来,我们会接着判断 icsk_accept_queue 是否为空,同时也会调用 signal_pending 看有没有信号可以处理。一旦 icsk_accept_queue 不为空,就从 inet_csk_wait_for_connect 中返回,在队列中取出一个 struct sock 对象赋值给 newsk。
解析 connect 函数
什么情况下,icsk_accept_queue 才不为空呢?当然是三次握手结束才可以。接下来我们来分析三次握手的过程。
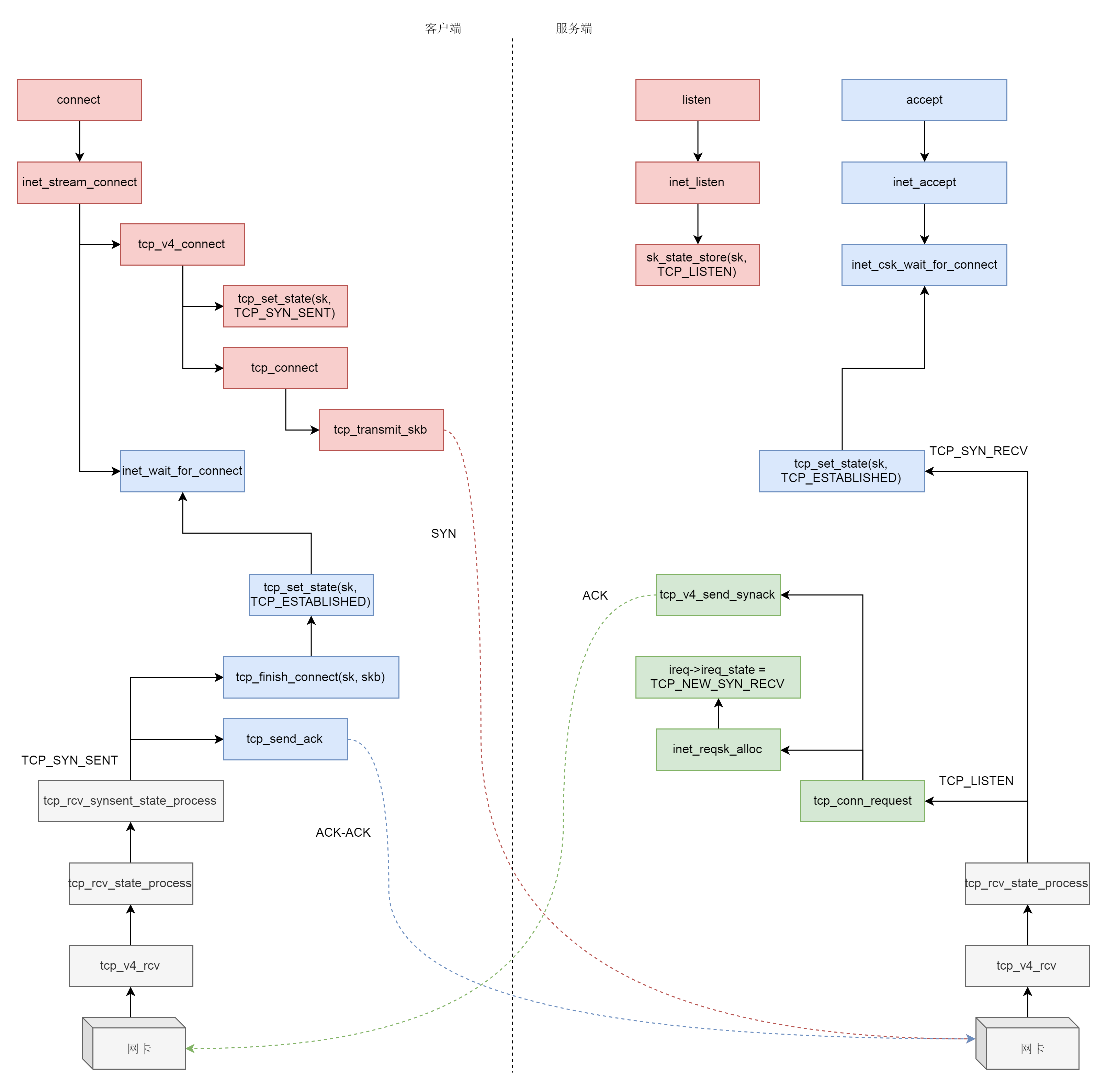
三次握手一般是由客户端调用 connect 发起。
connect 函数的实现一开始你应该很眼熟,还是通过 sockfd_lookup_light,根据 fd 文件描述符,找到 struct socket 结构。接着,我们会调用 struct socket 结构里面 ops 的 connect 函数,根据前面创建 socket 的时候的设定,调用 inet_stream_ops 的 connect 函数,也即调用 inet_stream_connect。
在 __inet_stream_connect 里面,我们发现,如果 socket 处于 SS_UNCONNECTED 状态,那就调用 struct sock 的 sk->sk_prot->connect,也即 tcp_prot 的 connect 函数——tcp_v4_connect 函数。
在 tcp_v4_connect 函数中,ip_route_connect 其实是做一个路由的选择。为什么呢?因为三次握手马上就要发送一个 SYN 包了,这就要凑齐源地址、源端口、目标地址、目标端口。目标地址和目标端口是服务端的,已经知道源端口是客户端随机分配的,源地址应该用哪一个呢?这时候要选择一条路由,看从哪个网卡出去,就应该填写哪个网卡的 IP 地址。
接下来,在发送 SYN 之前,我们先将客户端 socket 的状态设置为 TCP_SYN_SENT。然后初始化 TCP 的 seq num,也即 write_seq,然后调用 tcp_connect 进行发送。
在 tcp_connect 中,有一个新的结构 struct tcp_sock,如果打开他,你会发现他是 struct inet_connection_sock 的一个扩展,struct inet_connection_sock 在 struct tcp_sock 开头的位置,通过强制类型转换访问,故伎重演又一次。
struct tcp_sock 里面维护了更多的 TCP 的状态,咱们同样是遇到了再分析。
接下来 tcp_init_nondata_skb 初始化一个 SYN 包,tcp_transmit_skb 将 SYN 包发送出去,inet_csk_reset_xmit_timer 设置了一个 timer,如果 SYN 发送不成功,则再次发送。
发送网络包的过程,我们放到下一节讲解。这里我们姑且认为 SYN 已经发送出去了。
我们回到 __inet_stream_connect 函数,在调用 sk->sk_prot->connect 之后,inet_wait_for_connect 会一直等待客户端收到服务端的 ACK。而我们知道,服务端在 accept 之后,也是在等待中。
网络包是如何接收的呢?对于解析的详细过程,我们会在下下节讲解,这里为了解析三次握手,我们简单的看网络包接收到 TCP 层做的部分事情。
我们通过 struct net_protocol 结构中的 handler 进行接收,调用的函数是 tcp_v4_rcv。接下来的调用链为 tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_state_process。tcp_rcv_state_process,顾名思义,是用来处理接收一个网络包后引起状态变化的。
目前服务端是处于 TCP_LISTEN 状态的,而且发过来的包是 SYN,因而就有了上面的代码,调用 icsk->icsk_af_ops->conn_request 函数。struct inet_connection_sock 对应的操作是 inet_connection_sock_af_ops,按照下面的定义,其实调用的是 tcp_v4_conn_request。
tcp_v4_conn_request 会调用 tcp_conn_request,这个函数也比较长,里面调用了 send_synack,但实际调用的是 tcp_v4_send_synack。具体发送的过程我们不去管它,看注释我们能知道,这是收到了 SYN 后,回复一个 SYN-ACK,回复完毕后,服务端处于 TCP_SYN_RECV。
这个时候,轮到客户端接收网络包了。都是 TCP 协议栈,所以过程和服务端没有太多区别,还是会走到 tcp_rcv_state_process 函数的,只不过由于客户端目前处于 TCP_SYN_SENT 状态,就进入了下面的代码分支。
tcp_rcv_synsent_state_process 会调用 tcp_send_ack,发送一个 ACK-ACK,发送后客户端处于 TCP_ESTABLISHED 状态。
又轮到服务端接收网络包了,我们还是归 tcp_rcv_state_process 函数处理。由于服务端目前处于状态 TCP_SYN_RECV 状态,因而又走了另外的分支。当收到这个网络包的时候,服务端也处于 TCP_ESTABLISHED 状态,三次握手结束。
总结时刻
这一节除了网络包的接收和发送,其他的系统调用我们都分析到了。可以看出来,它们有一个统一的数据结构和流程。具体如下图所示:
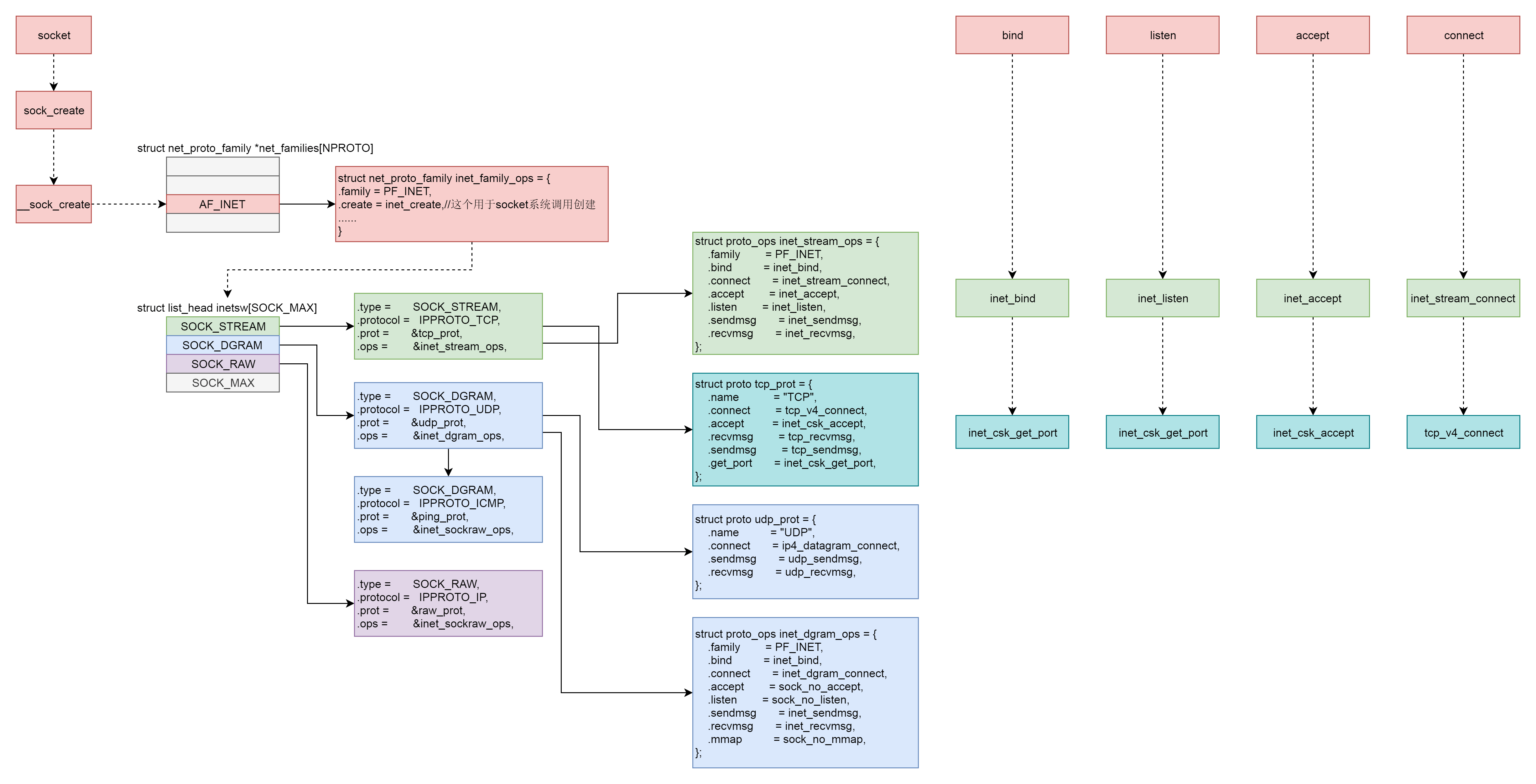
首先,Socket 系统调用会有三级参数 family、type、protocal,通过这三级参数,分别在 net_proto_family 表中找到 type 链表,在 type 链表中找到 protocal 对应的操作。这个操作分为两层,对于 TCP 协议来讲,第一层是 inet_stream_ops 层,第二层是 tcp_prot 层。
于是,接下来的系统调用规律就都一样了:
- bind 第一层调用 inet_stream_ops 的 inet_bind 函数,第二层调用 tcp_prot 的 inet_csk_get_port 函数;
- listen 第一层调用 inet_stream_ops 的 inet_listen 函数,第二层调用 tcp_prot 的 inet_csk_get_port 函数;
- accept 第一层调用 inet_stream_ops 的 inet_accept 函数,第二层调用 tcp_prot 的 inet_csk_accept 函数;
- connect 第一层调用 inet_stream_ops 的 inet_stream_connect 函数,第二层调用 tcp_prot 的 tcp_v4_connect 函数。
课堂练习
TCP 的三次握手协议非常重要,请你务必跟着代码走读一遍。另外我们这里重点关注了 TCP 的场景,请走读代码的时候,也看一下 UDP 是如何实现各层的函数的。
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

精选留言(2)
 飞翔2019-07-08syn到底是个什么东西呀?是个integer还是char类型展开
飞翔2019-07-08syn到底是个什么东西呀?是个integer还是char类型展开 杨怀2019-07-08老师好,同一个TCP链接上先后发送2次rpc请求,后发送的请求其结果先返回,先发送的请求结果后返回,这样有没有问题呢,系统能区分各自的返回结果么,靠什么机制保证的呢?一直没有想明白展开
杨怀2019-07-08老师好,同一个TCP链接上先后发送2次rpc请求,后发送的请求其结果先返回,先发送的请求结果后返回,这样有没有问题呢,系统能区分各自的返回结果么,靠什么机制保证的呢?一直没有想明白展开

