35 | 块设备(下):如何建立代理商销售模式?





讲述:刘超
时长19:05大小15.30M
在文件系统那一节,我们讲了文件的写入,到了设备驱动这一层,就没有再往下分析。上一节我们又讲了 mount 一个块设备,将 block_device 信息放到了 ext4 文件系统的 super_block 里面,有了这些基础,是时候把整个写入的故事串起来了。
还记得咱们在文件系统那一节分析写入流程的时候,对于 ext4 文件系统,最后调用的是 ext4_file_write_iter,它将 I/O 的调用分成两种情况:
第一是直接 I/O。最终我们调用的是 generic_file_direct_write,这里调用的是 mapping->a_ops->direct_IO,实际调用的是 ext4_direct_IO,往设备层写入数据。
第二种是缓存 I/O。最终我们会将数据从应用拷贝到内存缓存中,但是这个时候,并不执行真正的 I/O 操作。它们只将整个页或其中部分标记为脏。写操作由一个 timer 触发,那个时候,才调用 wb_workfn 往硬盘写入页面。
接下来的调用链为:wb_workfn->wb_do_writeback->wb_writeback->writeback_sb_inodes->__writeback_single_inode->do_writepages。在 do_writepages 中,我们要调用 mapping->a_ops->writepages,但实际调用的是 ext4_writepages,往设备层写入数据。
这一节,我们就沿着这两种情况分析下去。
直接 I/O 如何访问块设备?
我们先来看第一种情况,直接 I/O 调用到 ext4_direct_IO。
在 ext4_direct_IO_write 调用 __blockdev_direct_IO,有个参数你需要特别注意一下,那就是 inode->i_sb->s_bdev。通过当前文件的 inode,我们可以得到 super_block。这个 super_block 中的 s_bdev,就是咱们上一节填进去的那个 block_device。
__blockdev_direct_IO 会调用 do_blockdev_direct_IO,在这里面我们要准备一个 struct dio 结构和 struct dio_submit 结构,用来描述将要发生的写入请求。
do_direct_IO 里面有两层循环,第一层循环是依次处理这次要写入的所有块。对于每一块,取出对应的内存中的页 page,在这一块中,有写入的起始地址 from 和终止地址 to,所以,第二层循环就是依次处理 from 到 to 的数据,调用 submit_page_section,提交到块设备层进行写入。
submit_page_section 会调用 dio_bio_submit,进而调用 submit_bio 向块设备层提交数据。其中,参数 struct bio 是将数据传给块设备的通用传输对象。定义如下:
缓存 I/O 如何访问块设备?
我们再来看第二种情况,缓存 I/O 调用到 ext4_writepages。这个函数比较长,我们这里只截取最重要的部分来讲解。
这里比较重要的一个数据结构是 struct mpage_da_data。这里面有文件的 inode、要写入的页的偏移量,还有一个重要的 struct ext4_io_submit,里面有通用传输对象 bio。
在 ext4_writepages 中,mpage_prepare_extent_to_map 用于初始化这个 struct mpage_da_data 结构。接下来的调用链为:mpage_prepare_extent_to_map->mpage_process_page_bufs->mpage_submit_page->ext4_bio_write_page->io_submit_add_bh。
在 io_submit_add_bh 中,此时的 bio 还是空的,因而我们要调用 io_submit_init_bio,初始化 bio。
我们再回到 ext4_writepages 中。在 bio 初始化完之后,我们要调用 ext4_io_submit,提交 I/O。在这里我们又是调用 submit_bio,向块设备层传输数据。ext4_io_submit 的实现如下:
如何向块设备层提交请求?
既然无论是直接 I/O,还是缓存 I/O,最后都到了 submit_bio 里面,我们就来重点分析一下它。
submit_bio 会调用 generic_make_request。代码如下:
这里的逻辑有点复杂,我们先来看大的逻辑。在 do-while 中,我们先是获取一个请求队列 request_queue,然后调用这个队列的 make_request_fn 函数。
块设备队列结构
如果再来看 struct block_device 结构和 struct gendisk 结构,我们会发现,每个块设备都有一个请求队列 struct request_queue,用于处理上层发来的请求。
在每个块设备的驱动程序初始化的时候,会生成一个 request_queue。
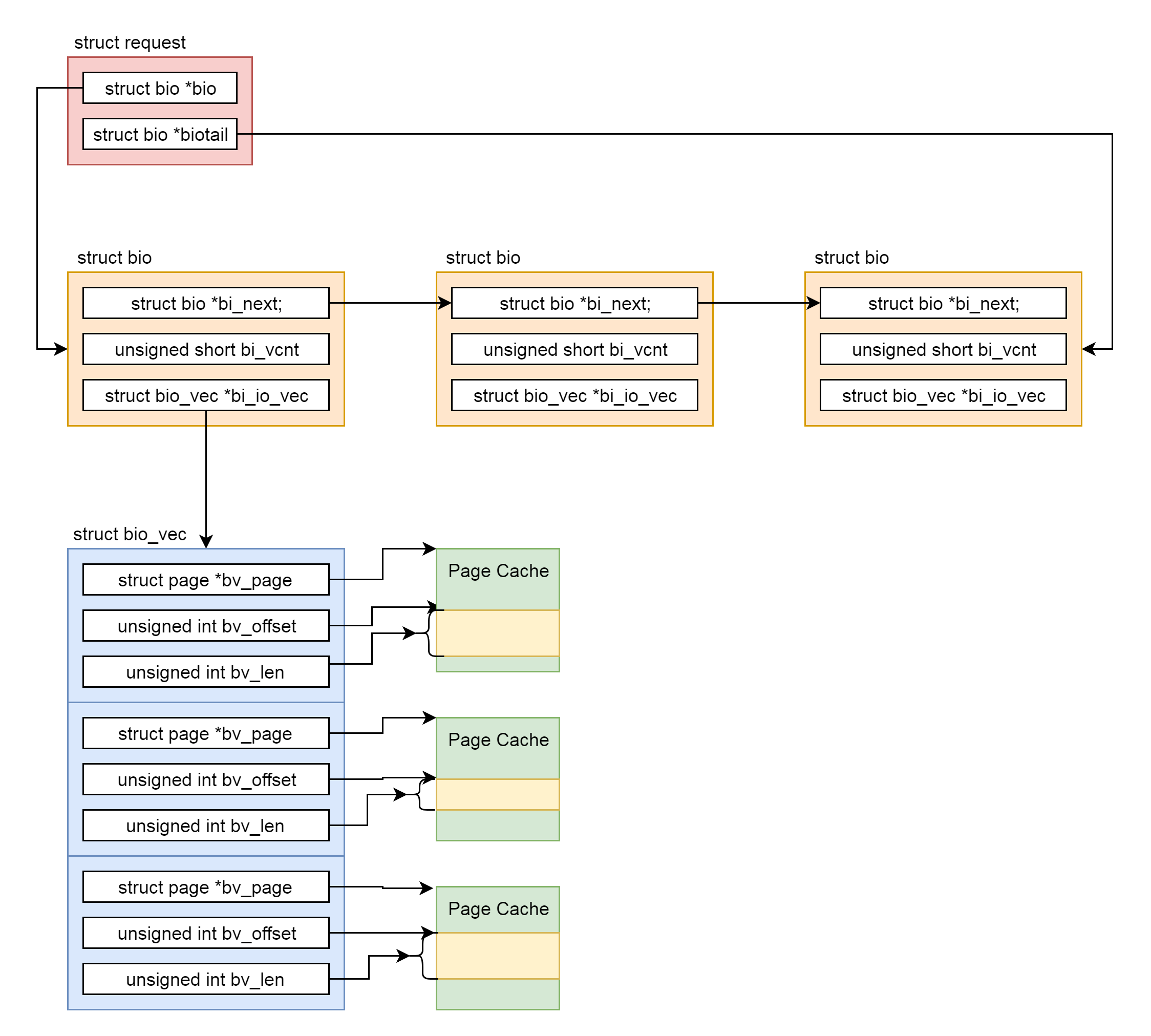
在请求队列 request_queue 上,首先是有一个链表 list_head,保存请求 request。
每个 request 包括一个链表的 struct bio,有指针指向一头一尾。
在 bio 中,bi_next 是链表中的下一项,struct bio_vec 指向一组页面。
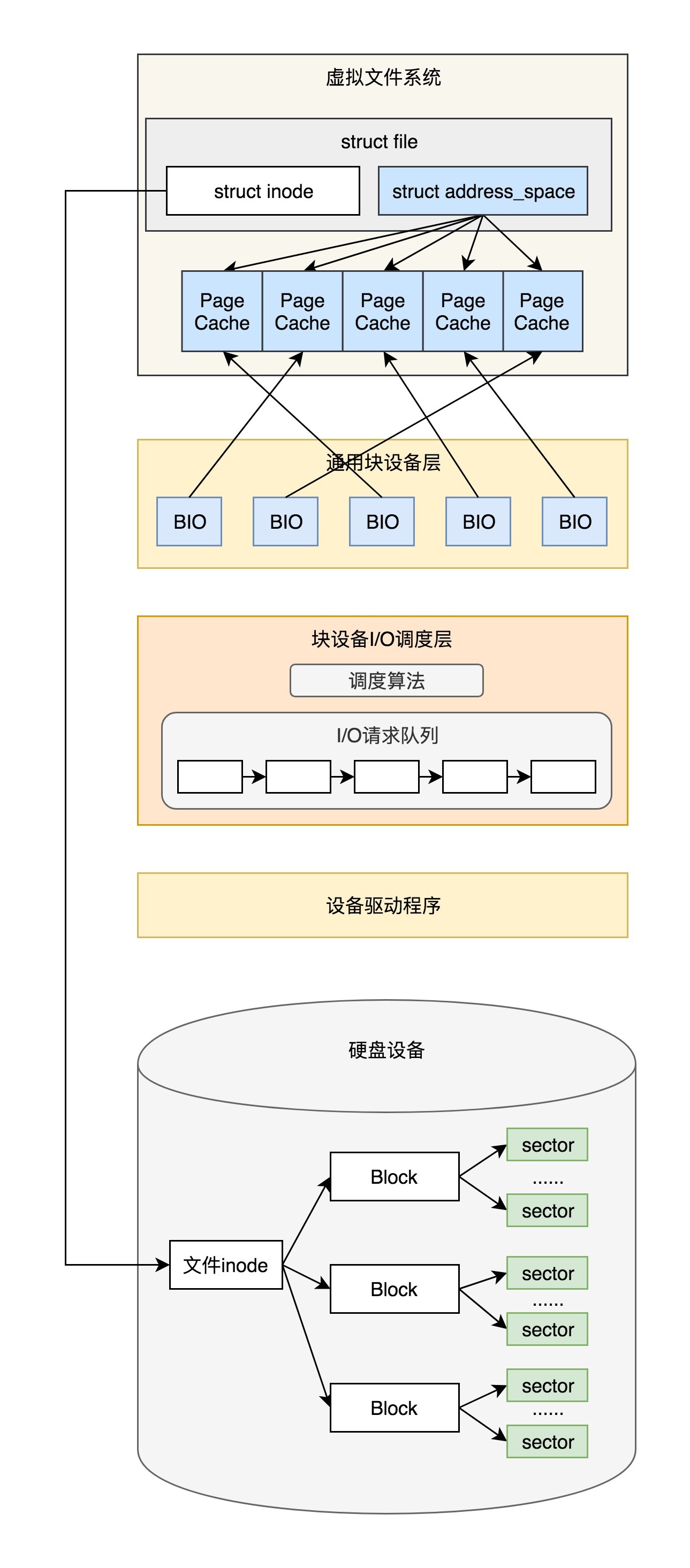
在请求队列 request_queue 上,还有两个重要的函数,一个是 make_request_fn 函数,用于生成 request;另一个是 request_fn 函数,用于处理 request。
块设备的初始化
我们还是以 scsi 驱动为例。在初始化设备驱动的时候,我们会调用 scsi_alloc_queue,把 request_fn 设置为 scsi_request_fn。我们还会调用 blk_init_allocated_queue->blk_queue_make_request,把 make_request_fn 设置为 blk_queue_bio。
在 blk_init_allocated_queue 中,除了初始化 make_request_fn 函数,我们还要做一件很重要的事情,就是初始化 I/O 的电梯算法。
电梯算法有很多种类型,定义为 elevator_type。下面我来逐一说一下。
- struct elevator_type elevator_noop
Noop 调度算法是最简单的 IO 调度算法,它将 IO 请求放入到一个 FIFO 队列中,然后逐个执行这些 IO 请求。
- struct elevator_type iosched_deadline
Deadline 算法要保证每个 IO 请求在一定的时间内一定要被服务到,以此来避免某个请求饥饿。为了完成这个目标,算法中引入了两类队列,一类队列用来对请求按起始扇区序号进行排序,通过红黑树来组织,我们称为 sort_list,按照此队列传输性能会比较高;另一类队列对请求按它们的生成时间进行排序,由链表来组织,称为 fifo_list,并且每一个请求都有一个期限值。
- struct elevator_type iosched_cfq
又看到了熟悉的 CFQ 完全公平调度算法。所有的请求会在多个队列中排序。同一个进程的请求,总是在同一队列中处理。时间片会分配到每个队列,通过轮询算法,我们保证了 I/O 带宽,以公平的方式,在不同队列之间进行共享。
elevator_init 中会根据名称来指定电梯算法,如果没有选择,那就默认使用 iosched_cfq。
请求提交与调度
接下来,我们回到 generic_make_request 函数中。调用队列的 make_request_fn 函数,其实就是调用 blk_queue_bio。
blk_queue_bio 首先做的一件事情是调用 elv_merge 来判断,当前这个 bio 请求是否能够和目前已有的 request 合并起来,成为同一批 I/O 操作,从而提高读取和写入的性能。
判断标准和 struct bio 的成员 struct bvec_iter 有关,它里面有两个变量,一个是起始磁盘簇 bi_sector,另一个是大小 bi_size。
elv_merge 尝试了三次合并。
第一次,它先判断和上一次合并的 request 能不能再次合并,看看能不能赶上马上要走的这部电梯。在 blk_try_merge 主要做了这样的判断:如果 blk_rq_pos(rq) + blk_rq_sectors(rq) == bio->bi_iter.bi_sector,也就是说这个 request 的起始地址加上它的大小(其实是这个 request 的结束地址),如果和 bio 的起始地址能接得上,那就把 bio 放在 request 的最后,我们称为 ELEVATOR_BACK_MERGE。
如果 blk_rq_pos(rq) - bio_sectors(bio) == bio->bi_iter.bi_sector,也就是说,这个 request 的起始地址减去 bio 的大小等于 bio 的起始地址,这说明 bio 放在 request 的最前面能够接得上,那就把 bio 放在 request 的最前面,我们称为 ELEVATOR_FRONT_MERGE。否则,那就不合并,我们称为 ELEVATOR_NO_MERGE。
第二次,如果和上一个合并过的 request 无法合并,那我们就调用 elv_rqhash_find。然后按照 bio 的起始地址查找 request,看有没有能够合并的。如果有的话,因为是按照起始地址找的,应该接在人家的后面,所以是 ELEVATOR_BACK_MERGE。
第三次,调用 elevator_merge_fn 试图合并。对于 iosched_cfq,调用的是 cfq_merge。在这里面,cfq_find_rq_fmerge 会调用 elv_rb_find 函数,里面的参数是 bio 的结束地址。我们还是要看,能不能找到可以合并的。如果有的话,因为是按照结束地址找的,应该接在人家前面,所以是 ELEVATOR_FRONT_MERGE。
等从 elv_merge 返回 blk_queue_bio 的时候,我们就知道,应该做哪种类型的合并,接着就要进行真的合并。如果没有办法合并,那就调用 get_request,创建一个新的 request,调用 blk_init_request_from_bio,将 bio 放到新的 request 里面,然后调用 add_acct_request,把新的 request 加到 request_queue 队列中。
至此,我们解析完了 generic_make_request 中最重要的两大逻辑:获取一个请求队列 request_queue 和调用这个队列的 make_request_fn 函数。
其实,generic_make_request 其他部分也很令人困惑。感觉里面有特别多的 struct bio_list,倒腾过来,倒腾过去的。这是因为,很多块设备是有层次的。
比如,我们用两块硬盘组成 RAID,两个 RAID 盘组成 LVM,然后我们就可以在 LVM 上创建一个块设备给用户用,我们称接近用户的块设备为高层次的块设备,接近底层的块设备为低层次(lower)的块设备。这样,generic_make_request 把 I/O 请求发送给高层次的块设备的时候,会调用高层块设备的 make_request_fn,高层块设备又要调用 generic_make_request,将请求发送给低层次的块设备。虽然块设备的层次不会太多,但是对于代码 generic_make_request 来讲,这可是递归的调用,一不小心,就会递归过深,无法正常退出,而且内核栈的大小又非常有限,所以要比较小心。
这里你是否理解了 struct bio_list bio_list_on_stack[2] 的名字为什么叫 stack 呢?其实,将栈的操作变成对于队列的操作,队列不在栈里面,会大很多。每次 generic_make_request 被当前任务调用的时候,将 current->bio_list 设置为 bio_list_on_stack,并在 generic_make_request 的一开始就判断 current->bio_list 是否为空。如果不为空,说明已经在 generic_make_request 的调用里面了,就不必调用 make_request_fn 进行递归了,直接把请求加入到 bio_list 里面就可以了,这就实现了递归的及时退出。
如果 current->bio_list 为空,那我们就将 current->bio_list 设置为 bio_list_on_stack 后,进入 do-while 循环,做咱们分析过的 generic_make_request 的两大逻辑。但是,当前的队列调用 make_request_fn 的时候,在 make_request_fn 的具体实现中,会生成新的 bio。调用更底层的块设备,也会生成新的 bio,都会放在 bio_list_on_stack 的队列中,是一个边处理还边创建的过程。
bio_list_on_stack[1] = bio_list_on_stack[0] 这一句在 make_request_fn 之前,将之前队列里面遗留没有处理的保存下来,接着 bio_list_init 将 bio_list_on_stack[0] 设置为空,然后调用 make_request_fn,在 make_request_fn 里面如果有新的 bio 生成,都会加到 bio_list_on_stack[0] 这个队列里面来。
make_request_fn 执行完毕后,可以想象 bio_list_on_stack[0] 可能又多了一些 bio 了,接下来的循环中调用 bio_list_pop 将 bio_list_on_stack[0] 积攒的 bio 拿出来,分别放在两个队列 lower 和 same 中,顾名思义,lower 就是更低层次的块设备的 bio,same 是同层次的块设备的 bio。
接下来我们能将 lower、same 以及 bio_list_on_stack[1] 都取出来,放在 bio_list_on_stack[0] 统一进行处理。当然应该 lower 优先了,因为只有底层的块设备的 I/O 做完了,上层的块设备的 I/O 才能做完。
到这里,generic_make_request 的逻辑才算解析完毕。对于写入的数据来讲,其实仅仅到将 bio 请求放在请求队列上,设备驱动程序还没往设备里面写呢。
请求的处理
设备驱动程序往设备里面写,调用的是请求队列 request_queue 的另外一个函数 request_fn。对于 scsi 设备来讲,调用的是 scsi_request_fn。
在这里面是一个 for 无限循环,从 request_queue 中读取 request,然后封装更加底层的指令,给设备控制器下指令,实施真正的 I/O 操作。
总结时刻
这一节我们讲了如何将块设备 I/O 请求送达到外部设备。
对于块设备的 I/O 操作分为两种,一种是直接 I/O,另一种是缓存 I/O。无论是哪种 I/O,最终都会调用 submit_bio 提交块设备 I/O 请求。
对于每一种块设备,都有一个 gendisk 表示这个设备,它有一个请求队列,这个队列是一系列的 request 对象。每个 request 对象里面包含多个 BIO 对象,指向 page cache。所谓的写入块设备,I/O 就是将 page cache 里面的数据写入硬盘。
对于请求队列来讲,还有两个函数,一个函数叫 make_request_fn 函数,用于将请求放入队列。submit_bio 会调用 generic_make_request,然后调用这个函数。
另一个函数往往在设备驱动程序里实现,我们叫 request_fn 函数,它用于从队列里面取出请求来,写入外部设备。
至此,整个写入文件的过程才完整结束。这真是个复杂的过程,涉及系统调用、内存管理、文件系统和输入输出。这足以说明,操作系统真的是一个非常复杂的体系,环环相扣,需要分层次层层展开来学习。
到这里,专栏已经过半了,你应该能发现,很多我之前说“后面会细讲”的东西,现在正在一点一点解释清楚,而文中越来越多出现“前面我们讲过”的字眼,你是否当时学习前面知识的时候,没有在意,导致学习后面的知识产生困惑了呢?没关系,及时倒回去复习,再回过头去看,当初学过的很多知识会变得清晰很多。
课堂练习
你知道如何查看磁盘调度算法、修改磁盘调度算法以及 I/O 队列的长度吗?
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

精选留言(11)
 莫名2019-06-17一堆代码分析,感觉脱离了所谓的趣谈😂 12
莫名2019-06-17一堆代码分析,感觉脱离了所谓的趣谈😂 12- 安排2019-06-17看了一点儿其它的资料,大概了解了一下,有以下几种情况:1、request_fn是在unplug泄流的时候调用(也就是队列里面的请求达到一定的数量) 2、或者是由定时器触发,也就是即使队列里面的请求很少,但是也不能无限期的不执行它们,所以在定时器超时后会调用request_fn 3、或者在添加request进行合并的时候,判断一下是哪种合并方式,如果是后向合并就会立即调用requset_fn。
不知道这样理解的对不对? 2  小美2019-06-19会不会断电丢失数据呢? 1
小美2019-06-19会不会断电丢失数据呢? 1- Leon📷2019-06-17那个队列,队头和队尾的合并都是为了所谓的顺序写,减少机械硬盘寻址消耗吧,能赶上就上同一辆车,赶不上自己叫一辆车等满了再走,但是也是有超时等待时间的,可以这么理解吧 1
- 安排2019-06-17往设备里面写的时候调用的是request_fn,这个函数是谁来调用的呢?触发这个调用的时机是什么呢?还是说请求一旦进入队列就会立即写入? 1
- Geek_54edc12019-06-24/sys/block/xvda/queue/scheduler 磁盘的调度算法,临时修改:echo noop > /sys/block/xvda/queue/scheduler,永久修改就需要修改内核参数,然后重启。
iostat -d -x 中的avgqu-sz是平均I/O队列长度。 - Leon📷2019-06-22文件系统中的page_cache对应逻辑上的块的概念,将page_cache打包成bio递交给通用块设备层,通用块设备层将多个bio打包成一个请求request, 尽量把bio对应的sector临近的数据合并,提交给块设备调度层,块设备调度层就是把各个request当成段提交给设备驱动程序,因为设备驱动程序只识别段,也就是说通用块设备层捣腾的其实就是把bio对应的页框和在磁盘中对应的sector进行合并的过程,调度层只负责把合并的request放进队列,用调度算法下发给驱动程序处理,其实所有复杂的合并操作以及内存和磁盘扇区的对应关系都是通过块设备层做了,老师,可以这么理解吧
- 安排2019-06-19老师,希望在答疑篇能讲一讲request_fn取出请求之后的具体执行过程,具体的执行是不是和block_device有关,磁盘的最底层的操作是不是都在block_device中?
- 安排2019-06-18直接读写裸设备不会走文件系统,那还会走通用块层吗?
- 安排2019-06-18make_request_fn被初始化成了blk_queue_bio函数。submit_bio会调用到generic_make_request,然后进一步调用到make_request_fn,也就是blk_queue_bio。在blk_queue_bio里面其实是先尝试将bio合并到当前进程的plug_list里面的request,如果可以合并,则合并后直接返回了,如果不能合并,则接着向磁盘设备的request_queue中合并,向request_queue中合并的时候一定会成功(因为即使不能合并也会新生成一个request)。而每个进程的plug_list里面的request也会在适当的时候就行泄流,泄流的时候会调用到磁盘设备的request_queue里面的电梯成员的elevator_add_req_fn,这个函数就是讲plug_list里面的request加入到request_queue里面的电梯队列里,进行更进一步的合并。
设备驱动会调用request_queue的request_fn,平时写块设备驱动也就是申请一个request_queue,然后调用一些内核api初始化这个request_queue,并且实现自己的request_fn函数,request_fn会调用blk_peek_request从request_queue的queue_head成员取出request,并转化为更底层的指令来执行,如果发现queue_head为空,则会调用request_queue的elevator_dispatch_fn分发request。  石维康2019-06-17bio_list_merge(&bio_list_on_stack[0], &lower);
石维康2019-06-17bio_list_merge(&bio_list_on_stack[0], &lower);
bio_list_merge(&bio_list_on_stack[0], &same);
bio_list_merge(&bio_list_on_stack[0], &bio_list_on_stack[1]);
请问这些加到bio_list_on_stack[0]上的bio是在什么时候被处理的?




