34 | 块设备(上):如何建立代理商销售模式?





讲述:刘超
时长17:43大小16.24M
上一章,我们解析了文件系统,最后讲文件系统读写的流程到达底层的时候,没有更深入地分析下去,这是因为文件系统再往下就是硬盘设备了。上两节,我们解析了字符设备的 mknod、打开和读写流程。那这一节我们就来讲块设备的 mknod、打开流程,以及文件系统和下层的硬盘设备的读写流程。
块设备一般会被格式化为文件系统,但是,下面的讲述中,你可能会有一点困惑。你会看到各种各样的 dentry 和 inode。块设备涉及三种文件系统,所以你看到的这些 dentry 和 inode 可能都不是一回事儿,请注意分辨。
块设备需要 mknod 吗?对于启动盘,你可能觉得,启动了就在那里了。可是如果我们要插进一块新的 USB 盘,还是要有这个操作的。
mknod 还是会创建在 /dev 路径下面,这一点和字符设备一样。/dev 路径下面是 devtmpfs 文件系统。这是块设备遇到的第一个文件系统。我们会为这个块设备文件,分配一个特殊的 inode,这一点和字符设备也是一样的。只不过字符设备走 S_ISCHR 这个分支,对应 inode 的 file_operations 是 def_chr_fops;而块设备走 S_ISBLK 这个分支,对应的 inode 的 file_operations 是 def_blk_fops。这里要注意,inode 里面的 i_rdev 被设置成了块设备的设备号 dev_t,这个我们后面会用到,你先记住有这么一回事儿。
特殊 inode 的默认 file_operations 是 def_blk_fops,就像字符设备一样,有打开、读写这个块设备文件,但是我们常规操作不会这样做。我们会将这个块设备文件 mount 到一个文件夹下面。
不过,这里我们还是简单看一下,打开这个块设备的操作 blkdev_open。它里面调用的是 blkdev_get 打开这个块设备,了解到这一点就可以了。
接下来,我们要调用 mount,将这个块设备文件挂载到一个文件夹下面。如果这个块设备原来被格式化为一种文件系统的格式,例如 ext4,那我们调用的就是 ext4 相应的 mount 操作。这是块设备遇到的第二个文件系统,也是向这个块设备读写文件,需要基于的主流文件系统。咱们在文件系统那一节解析的对于文件的读写流程,都是基于这个文件系统的。
还记得,咱们注册 ext4 文件系统的时候,有下面这样的结构:
在将一个硬盘的块设备 mount 成为 ext4 的时候,我们会调用 ext4_mount->mount_bdev。
mount_bdev 主要做了两件大事情。第一,blkdev_get_by_path 根据 /dev/xxx 这个名字,找到相应的设备并打开它;第二,sget 根据打开的设备文件,填充 ext4 文件系统的 super_block,从而以此为基础,建立一整套咱们在文件系统那一章讲的体系。
一旦这套体系建立起来以后,对于文件的读写都是通过 ext4 文件系统这个体系进行的,创建的 inode 结构也是指向 ext4 文件系统的。文件系统那一章我们只解析了这部分,由于没有到达底层,也就没有关注块设备相关的操作。这一章我们重新回过头来,一方面看 mount 的时候,对于块设备都做了哪些操作,另一方面看读写的时候,到了底层,对于块设备做了哪些操作。
这里我们先来看 mount_bdev 做的第一件大事情,通过 blkdev_get_by_path,根据设备名 /dev/xxx,得到 struct block_device *bdev。
blkdev_get_by_path 干了两件事情。第一个,lookup_bdev 根据设备路径 /dev/xxx 得到 block_device。第二个,打开这个设备,调用 blkdev_get。
咱们上面分析过 def_blk_fops 的默认打开设备函数 blkdev_open,它也是调用 blkdev_get 的。块设备的打开往往不是直接调用设备文件的打开函数,而是调用 mount 来打开的。
lookup_bdev 这里的 pathname 是设备的文件名,例如 /dev/xxx。这个文件是在 devtmpfs 文件系统中的,kern_path 可以在这个文件系统里面,一直找到它对应的 dentry。接下来,d_backing_inode 会获得 inode。这个 inode 就是那个 init_special_inode 生成的特殊 inode。
接下来,bd_acquire 通过这个特殊的 inode,找到 struct block_device。
bd_acquire 中最主要的就是调用 bdget,它的参数是特殊 inode 的 i_rdev。这里面在 mknod 的时候,放的是设备号 dev_t。
在 bdget 中,我们遇到了第三个文件系统,bdev 伪文件系统。bdget 函数根据传进来的 dev_t,在 blockdev_superblock 这个文件系统里面找到 inode。这里注意,这个 inode 已经不是 devtmpfs 文件系统的 inode 了。blockdev_superblock 的初始化在整个系统初始化的时候,会调用 bdev_cache_init 进行初始化。它的定义如下:
所有表示块设备的 inode 都保存在伪文件系统 bdev 中,这些对用户层不可见,主要为了方便块设备的管理。Linux 将块设备的 block_device 和 bdev 文件系统的块设备的 inode,通过 struct bdev_inode 进行关联。所以,在 bdget 中,BDEV_I 就是通过 bdev 文件系统的 inode,获得整个 struct bdev_inode 结构的地址,然后取成员 bdev,得到 block_device。
绕了一大圈,我们终于通过设备文件 /dev/xxx,获得了设备的结构 block_device。有点儿绕,我们再捋一下。设备文件 /dev/xxx 在 devtmpfs 文件系统中,找到 devtmpfs 文件系统中的 inode,里面有 dev_t。我们可以通过 dev_t,在伪文件系统 bdev 中找到对应的 inode,然后根据 struct bdev_inode 找到关联的 block_device。
接下来,blkdev_get_by_path 开始做第二件事情,在找到 block_device 之后,要调用 blkdev_get 打开这个设备。blkdev_get 会调用 __blkdev_get。
在分析打开一个设备之前,我们先来看 block_device 这个结构是什么样的。
你应该能发现,这个结构和其他几个结构有着千丝万缕的联系,比较复杂。这是因为块设备本身就比较复杂。
比方说,我们有一个磁盘 /dev/sda,我们既可以把它整个格式化成一个文件系统,也可以把它分成多个分区 /dev/sda1、 /dev/sda2,然后把每个分区格式化成不同的文件系统。如果我们访问某个分区的设备文件 /dev/sda2,我们应该能知道它是哪个磁盘设备的。按说它们的驱动应该是一样的。如果我们访问整个磁盘的设备文件 /dev/sda,我们也应该能知道它分了几个区域,所以就有了下图这个复杂的关系结构。
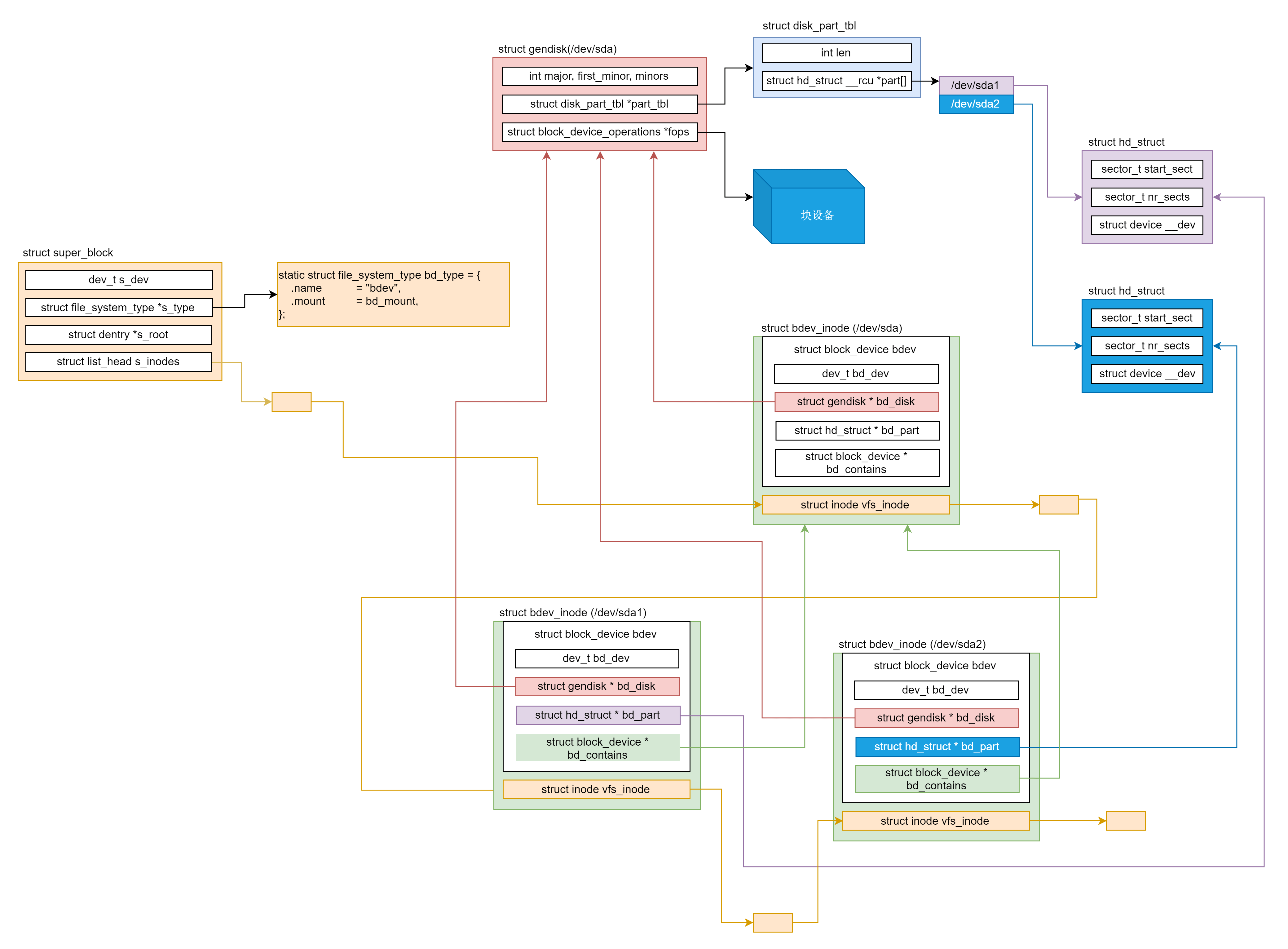
struct gendisk 是用来描述整个设备的,因而上面的例子中,gendisk 只有一个实例,指向 /dev/sda。它的定义如下:
这里 major 是主设备号,first_minor 表示第一个分区的从设备号,minors 表示分区的数目。
disk_name 给出了磁盘块设备的名称。
struct disk_part_tbl 结构里是一个 struct hd_struct 的数组,用于表示各个分区。struct block_device_operations fops 指向对于这个块设备的各种操作。struct request_queue queue 是表示在这个块设备上的请求队列。
struct hd_struct 是用来表示某个分区的,在上面的例子中,有两个 hd_struct 的实例,分别指向 /dev/sda1、 /dev/sda2。它的定义如下:
在 hd_struct 中,比较重要的成员变量保存了如下的信息:从磁盘的哪个扇区开始,到哪个扇区结束。
而 block_device 既可以表示整个块设备,也可以表示某个分区,所以对于上面的例子,block_device 有三个实例,分别指向 /dev/sda1、/dev/sda2、/dev/sda。
block_device 的成员变量 bd_disk,指向的 gendisk 就是整个块设备。这三个实例都指向同一个 gendisk。bd_part 指向的某个分区的 hd_struct,bd_contains 指向的是整个块设备的 block_device。
了解了这些复杂的关系,我们再来看打开设备文件的代码,就会清晰很多。
在 __blkdev_get 函数中,我们先调用 get_gendisk,根据 block_device 获取 gendisk。具体代码如下:
我们可以想象这里面有两种情况。第一种情况是,block_device 是指向整个磁盘设备的。这个时候,我们只需要根据 dev_t,在 bdev_map 中将对应的 gendisk 拿出来就好。
bdev_map 是干什么的呢?前面咱们学习字符设备驱动的时候讲过,任何一个字符设备初始化的时候,都需要调用 __register_chrdev_region,注册这个字符设备。对于块设备也是类似的,每一个块设备驱动初始化的时候,都会调用 add_disk 注册一个 gendisk。
这里需要说明一下,gen 的意思是 general 通用的意思,也就是说,所有的块设备,不仅仅是硬盘 disk,都会用一个 gendisk 来表示,然后通过调用链 add_disk->device_add_disk->blk_register_region,将 dev_t 和一个 gendisk 关联起来,保存在 bdev_map 中。
get_gendisk 要处理的第二种情况是,block_device 是指向某个分区的。这个时候我们要先得到 hd_struct,然后通过 hd_struct,找到对应的整个设备的 gendisk,并且把 partno 设置为分区号。
我们再回到 __blkdev_get 函数中,得到 gendisk。接下来我们可以分两种情况。
如果 partno 为 0,也就是说,打开的是整个设备而不是分区,那我们就调用 disk_get_part,获取 gendisk 中的分区数组,然后调用 block_device_operations 里面的 open 函数打开设备。
如果 partno 不为 0,也就是说打开的是分区,那我们就获取整个设备的 block_device,赋值给变量 struct block_device *whole,然后调用递归 __blkdev_get,打开 whole 代表的整个设备,将 bd_contains 设置为变量 whole。
block_device_operations 就是在驱动层了。例如在 drivers/scsi/sd.c 里面,也就是 MODULE_DESCRIPTION(“SCSI disk (sd) driver”) 中,就有这样的定义。
在驱动层打开了磁盘设备之后,我们可以看到,在这个过程中,block_device 相应的成员变量该填的都填上了,这才完成了 mount_bdev 的第一件大事,通过 blkdev_get_by_path 得到 block_device。
接下来就是第二件大事情,我们要通过 sget,将 block_device 塞进 superblock 里面。注意,调用 sget 的时候,有一个参数是一个函数 set_bdev_super。这里面将 block_device 设置进了 super_block。而 sget 要做的,就是分配一个 super_block,然后调用 set_bdev_super 这个 callback 函数。这里的 super_block 是 ext4 文件系统的 super_block。
sget(fs_type, test_bdev_super, set_bdev_super, flags | MS_NOSEC, bdev);
好了,到此为止,mount 中一个块设备的过程就结束了。设备打开了,形成了 block_device 结构,并且塞到了 super_block 中。
有了 ext4 文件系统的 super_block 之后,接下来对于文件的读写过程,就和文件系统那一章的过程一摸一样了。只要不涉及真正写入设备的代码,super_block 中的这个 block_device 就没啥用处。这也是为什么文件系统那一章,我们丝毫感觉不到它的存在,但是一旦到了底层,就到了 block_device 起作用的时候了,这个我们下一节仔细分析。
总结时刻
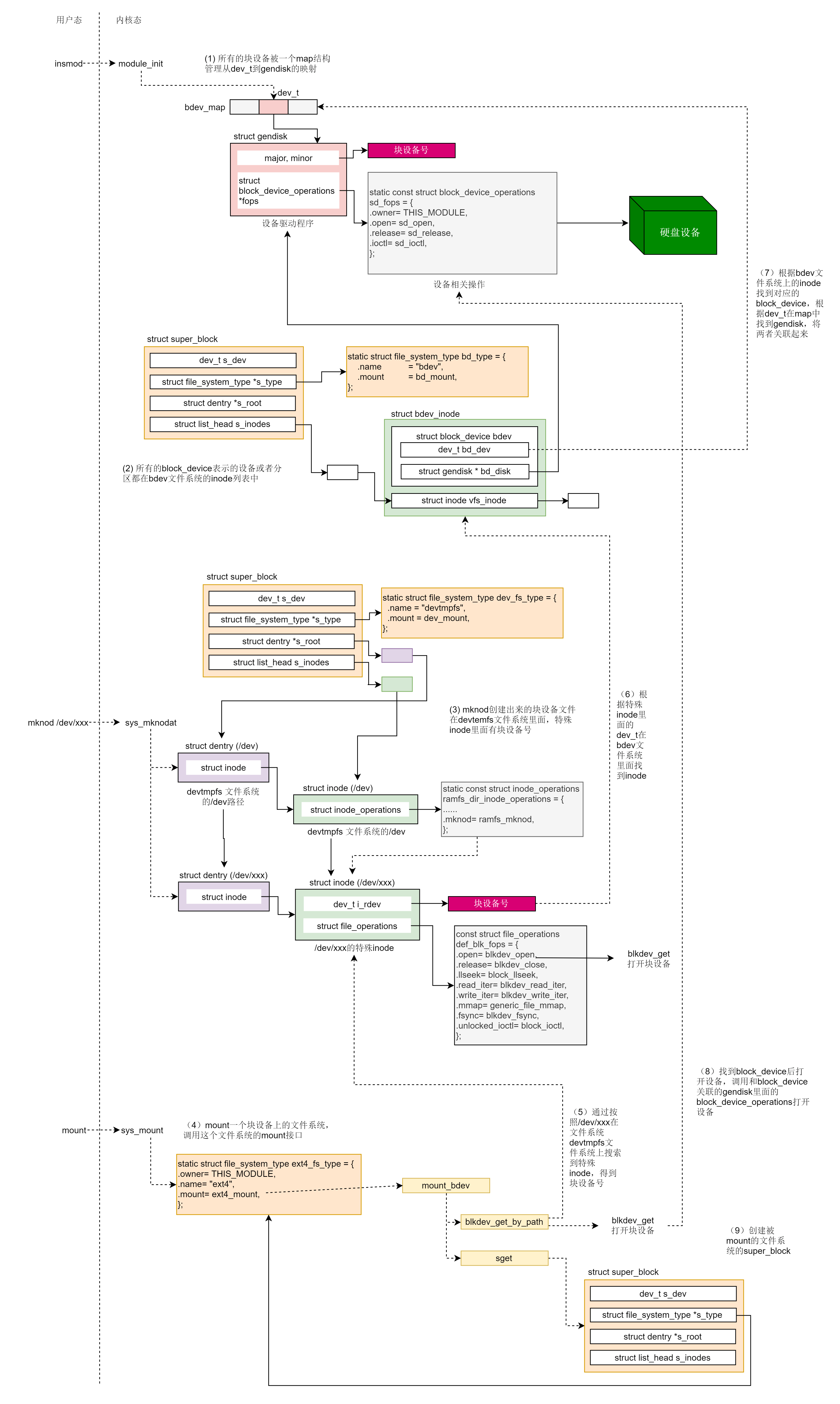
从这一节我们可以看出,块设备比字符设备复杂多了,涉及三个文件系统,工作过程我用一张图总结了一下,下面带你总结一下。
- 所有的块设备被一个 map 结构管理从 dev_t 到 gendisk 的映射;
- 所有的 block_device 表示的设备或者分区都在 bdev 文件系统的 inode 列表中;
- mknod 创建出来的块设备文件在 devtemfs 文件系统里面,特殊 inode 里面有块设备号;
- mount 一个块设备上的文件系统,调用这个文件系统的 mount 接口;
- 通过按照 /dev/xxx 在文件系统 devtmpfs 文件系统上搜索到特殊 inode,得到块设备号;
- 根据特殊 inode 里面的 dev_t 在 bdev 文件系统里面找到 inode;
- 根据 bdev 文件系统上的 inode 找到对应的 block_device,根据 dev_t 在 map 中找到 gendisk,将两者关联起来;
- 找到 block_device 后打开设备,调用和 block_device 关联的 gendisk 里面的 block_device_operations 打开设备;
- 创建被 mount 的文件系统的 super_block。
课堂练习
到这里,你是否真的体会到了 Linux 里面“一切皆文件”了呢?那个特殊的 inode 除了能够表示字符设备和块设备,还能表示什么呢?请你看代码分析一下。
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

精选留言(3)
- 安排2019-06-14bdev这个文件系统的内容是不会持久化到磁盘的,既然这样,那么为什么要组织成文件系统的形式呢?
对内存中的文件系统不太了解,下面是我的理解,希望老师给予指正:
bdev里面由各种数据结构组成,例如链表、树之类的。这些结构和通常的文件系统用的那些数据结构相同,而且组织成了和通常的文件系统类似的形式,所以这里就把bdev代表的这一对数据结构组成的东西叫做文件系统。 如果把bdev组织成和通常的文件系统大不相同的形式,是不是也可以完成本文中的功能?那么这时候就不把bdev叫做文件系统了,而它就是一堆普通的数据结构。展开 - 安排2019-06-14如果block_device是指向某个分区的,我们要先找到hd_struct,然后根据hd_struct找到对应整个设备的gendisk,这里是怎么根据hd_struct找到对应整个设备的gendisk的啊?展开
 小龙的城堡2019-06-14能解释下为什么打开一个块设备需要3个文件系统配合?为什么不是两个,也不是4个?感觉一堆代码分析,越来越晕了。展开
小龙的城堡2019-06-14能解释下为什么打开一个块设备需要3个文件系统配合?为什么不是两个,也不是4个?感觉一堆代码分析,越来越晕了。展开

