33 | 字符设备(下):如何建立直销模式?





讲述:刘超
时长15:52大小14.54M
上一节,我们讲了一个设备能够被打开、能够读写,主流的功能基本就完成了。我们讲输出输出设备的时候说到,如果一个设备有事情需要通知操作系统,会通过中断和设备驱动程序进行交互,今天我们就来解析中断处理机制。
鼠标就是通过中断,将自己的位置和按键信息,传递给设备驱动程序。
要处理中断,需要有一个中断处理函数。定义如下:
其中,irq 是一个整数,是中断信号。dev_id 是一个 void * 的通用指针,主要用于区分同一个中断处理函数对于不同设备的处理。
这里的返回值有三种:IRQ_NONE 表示不是我的中断,不归我管;IRQ_HANDLED 表示处理完了的中断;IRQ_WAKE_THREAD 表示有一个进程正在等待这个中断,中断处理完了,应该唤醒它。
上面的例子中,logibm_interrupt 这个中断处理函数,先是获取了 x 和 y 的移动坐标,以及左中右的按键,上报上去,然后返回 IRQ_HANDLED,这表示处理完毕。
其实,写一个真正生产用的中断处理程序还是很复杂的。当一个中断信号 A 触发后,正在处理的过程中,这个中断信号 A 是应该暂时关闭的,这样是为了防止再来一个中断信号 A,在当前的中断信号 A 的处理过程中插一杠子。但是,这个暂时关闭的时间应该多长呢?
如果太短了,应该原子化处理完毕的没有处理完毕,又被另一个中断信号 A 中断了,很多操作就不正确了;如果太长了,一直关闭着,新的中断信号 A 进不来,系统就显得很慢。所以,很多中断处理程序将整个中断要做的事情分成两部分,称为上半部和下半部,或者成为关键处理部分和延迟处理部分。在中断处理函数中,仅仅处理关键部分,完成了就将中断信号打开,使得新的中断可以进来,需要比较长时间处理的部分,也即延迟部分,往往通过工作队列等方式慢慢处理。
这个写起来可以是一本书了,推荐你好好读一读《Linux Device Drivers》这本书,这里我就不详细介绍了。
有了中断处理函数,接下来要调用 request_irq 来注册这个中断处理函数。request_irq 有这样几个参数:
- unsigned int irq 是中断信号;
- irq_handler_t handler 是中断处理函数;
- unsigned long flags 是一些标识位;
- const char *name 是设备名称;
- void *dev 这个通用指针应该和中断处理函数的 void *dev 相对应。
中断处理函数被注册到哪里去呢?让我们沿着 request_irq 看下去。request_irq 调用的是 request_threaded_irq。代码如下:
对于每一个中断,都有一个对中断的描述结构 struct irq_desc。它有一个重要的成员变量是 struct irqaction,用于表示处理这个中断的动作。如果我们仔细看这个结构,会发现,它里面有 next 指针,也就是说,这是一个链表,对于这个中断的所有处理动作,都串在这个链表上。
每一个中断处理动作的结构 struct irqaction,都有以下成员:
- 中断处理函数 handler;
- void *dev_id 为设备 id;
- irq 为中断信号;
- 如果中断处理函数在单独的线程运行,则有 thread_fn 是线程的执行函数,thread 是线程的 task_struct。
在 request_threaded_irq 函数中,irq_to_desc 根据中断信号查找中断描述结构。如何查找呢?这就要区分情况。一般情况下,所有的 struct irq_desc 都放在一个数组里面,我们直接按下标查找就可以了。如果配置了 CONFIG_SPARSE_IRQ,那中断号是不连续的,就不适合用数组保存了,
我们可以放在一棵基数树上。我们不是第一次遇到这个数据结构了。这种结构对于从某个整型 key 找到 value 速度很快,中断信号 irq 是这个整数。通过它,我们很快就能定位到对应的 struct irq_desc。
为什么中断信号会有稀疏,也就是不连续的情况呢?这里需要说明一下,这里的 irq 并不是真正的、物理的中断信号,而是一个抽象的、虚拟的中断信号。因为物理的中断信号和硬件关联比较大,中断控制器也是各种各样的。
作为内核,我们不可能写程序的时候,适配各种各样的硬件中断控制器,因而就需要有一层中断抽象层。这里虚拟中断信号到中断描述结构的映射,就是抽象中断层的主要逻辑。
下面我们讲真正中断响应的时候,会涉及物理中断信号。可以想象,如果只有一个 CPU,一个中断控制器,则基本能够保证从物理中断信号到虚拟中断信号的映射是线性的,这样用数组表示就没啥问题,但是如果有多个 CPU,多个中断控制器,每个中断控制器各有各的物理中断信号,就没办法保证虚拟中断信号是连续的,所以就要用到基数树了。
接下来,request_threaded_irq 函数分配了一个 struct irqaction,并且初始化它,接着调用 __setup_irq。在这个函数里面,如果 struct irq_desc 里面已经有 struct irqaction 了,我们就将新的 struct irqaction 挂在链表的末端。如果设定了以单独的线程运行中断处理函数,setup_irq_thread 就会创建这个内核线程,wake_up_process 会唤醒它。
至此为止,request_irq 完成了它的使命。总结来说,它就是根据中断信号 irq,找到基数树上对应的 irq_desc,然后将新的 irqaction 挂在链表上。
接下来,我们就来看,真正中断来了的时候,会发生一些什么。
真正中断的发生还是要从硬件开始。这里面有四个层次。
- 第一个层次是外部设备给中断控制器发送物理中断信号。
- 第二个层次是中断控制器将物理中断信号转换成为中断向量 interrupt vector,发给各个 CPU。
- 第三个层次是每个 CPU 都会有一个中断向量表,根据 interrupt vector 调用一个 IRQ 处理函数。注意这里的 IRQ 处理函数还不是咱们上面指定的 irq_handler_t,到这一层还是 CPU 硬件的要求。
- 第四个层次是在 IRQ 处理函数中,将 interrupt vector 转化为抽象中断层的中断信号 irq,调用中断信号 irq 对应的中断描述结构里面的 irq_handler_t。
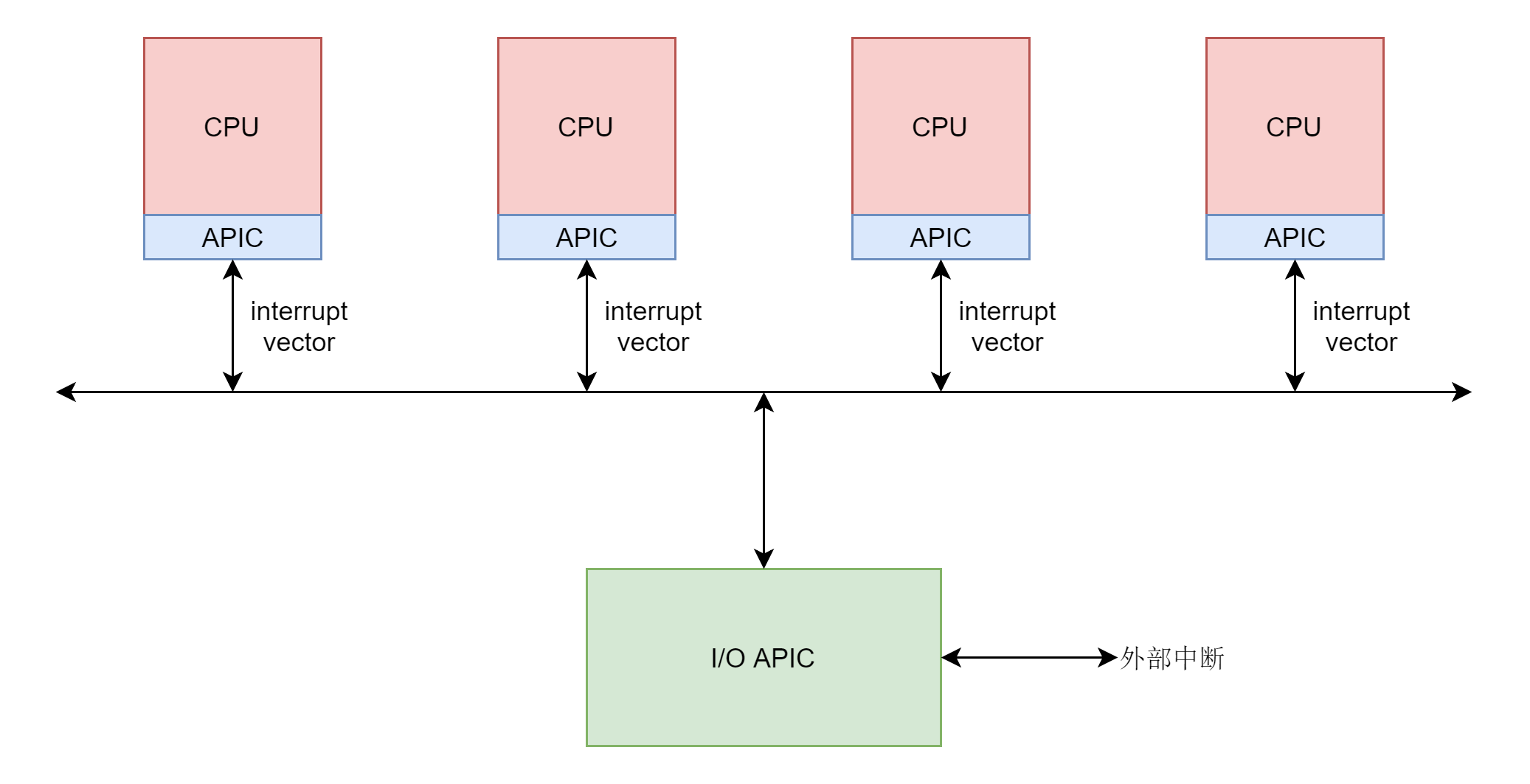
在这里,我们不解析硬件的部分,我们从 CPU 收到中断向量开始分析。
CPU 收到的中断向量是什么样的呢?这个定义在文件 arch/x86/include/asm/irq_vectors.h 中。这里面的注释非常好,建议你仔细阅读。
通过这些注释,我们可以看出,CPU 能够处理的中断总共 256 个,用宏 NR_VECTOR 或者 FIRST_SYSTEM_VECTOR 表示。
为了处理中断,CPU 硬件要求每一个 CPU 都有一个中断向量表,通过 load_idt 加载,里面记录着每一个中断对应的处理方法,这个中断向量表定义在文件 arch/x86/kernel/traps.c 中。
对于一个 CPU 可以处理的中断被分为几个部分,第一部分 0 到 31 的前 32 位是系统陷入或者系统异常,这些错误无法屏蔽,一定要处理。
这些中断的处理函数在系统初始化的时候,在 start_kernel 函数中调用过 trap_init()。这个咱们讲系统初始化和系统调用的时候,都大概讲过这个函数,这里还需要仔细看一下。
我这里贴的代码省略了很多,在 trap_init 函数的一开始,调用了大量的 set_intr_gate,最终都会调用 _set_gate,代码如下:
从代码可以看出,set_intr_gate 其实就是将每个中断都设置了中断处理函数,放在中断向量表 idt_table 中。
在 trap_init 中,由于 set_intr_gate 调用的太多,容易让人眼花缭乱。其实 arch/x86/include/asm/traps.h 文件中,早就定义好了前 32 个中断。如果仔细对比一下,你会发现,这些都在 trap_init 中使用 set_intr_gate 设置过了。
我们回到 trap_init 中,当前 32 个中断都用 set_intr_gate 设置完毕。在中断向量表 idt_table 中填完了之后,接下来的 for 循环,for (i = 0; i < FIRST_EXTERNAL_VECTOR; i++),将前 32 个中断都在 used_vectors 中标记为 1,表示这些都设置过中断处理函数了。
接下来,trap_init 对单独调用 set_intr_gate 来设置 32 位系统调用的中断。IA32_SYSCALL_VECTOR,也即 128,单独将 used_vectors 中的第 128 位标记为 1。
在 trap_init 的最后,我们将 idt_table 放在一个固定的虚拟地址上。trap_init 结束后,中断向量表中已经填好了前 32 位,外加一位 32 位系统调用,其他的都是用于设备中断。
在 start_kernel 调用完毕 trap_init 之后,还会调用 init_IRQ() 来初始化其他的设备中断,最终会调用到 native_init_IRQ。
这里面从第 32 个中断开始,到最后 NR_VECTORS 为止,对于 used_vectors 中没有标记为 1 的位置,都会调用 set_intr_gate 设置中断向量表。
其实 used_vectors 中没有标记为 1 的,都是设备中断的部分。
也即所有的设备中断的中断处理函数,在中断向量表里面都会设置为从 irq_entries_start 开始,偏移量为 i - FIRST_EXTERNAL_VECTOR 的一项。
看来中断处理函数是定义在 irq_entries_start 这个表里面的,我们在 arch\x86\entry\entry_32.S 和 arch\x86\entry\entry_64.S 都能找到这个函数表的定义。
这又是汇编语言,不需要完全看懂,但是我们还是能看出来,这里面定义了 FIRST_SYSTEM_VECTOR - FIRST_EXTERNAL_VECTOR 项。每一项都是中断处理函数,会跳到 common_interrupt 去执行。这里会最终调用 do_IRQ,调用完毕后,就从中断返回。这里我们需要区分返回用户态还是内核态。这里会有一个几乎触发抢占,咱们讲进程切换的时候讲过的。
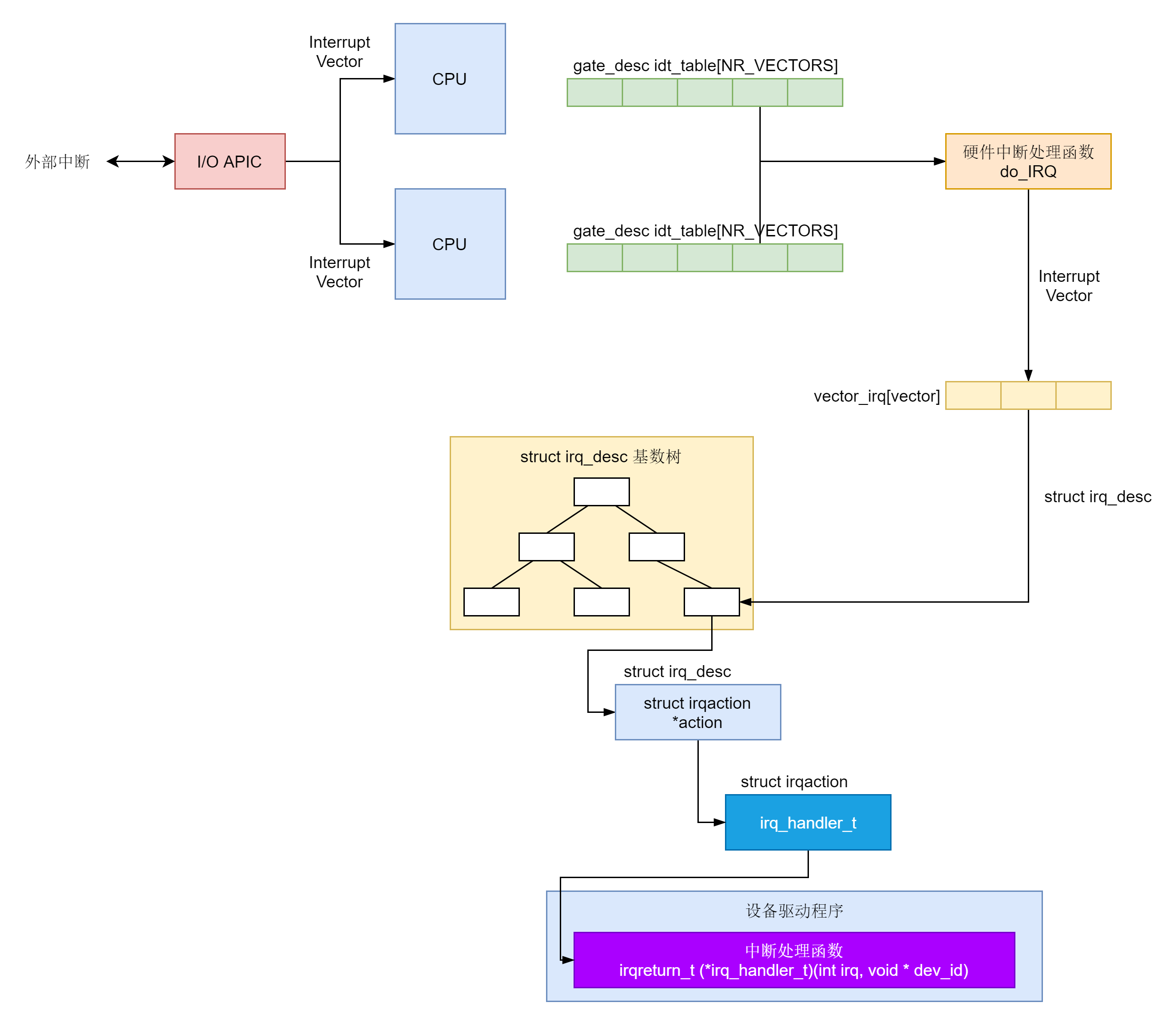
这样任何一个中断向量到达任何一个 CPU,最终都会走到 do_IRQ。我们来看 do_IRQ 的实现。
在这里面,从 AX 寄存器里面拿到了中断向量 vector,但是别忘了中断控制器发送给每个 CPU 的中断向量都是每个 CPU 局部的,而抽象中断处理层的虚拟中断信号 irq 以及它对应的中断描述结构 irq_desc 是全局的,也即这个 CPU 的 200 号的中断向量和另一个 CPU 的 200 号中断向量对应的虚拟中断信号 irq 和中断描述结构 irq_desc 可能不一样,这就需要一个映射关系。这个映射关系放在 Per CPU 变量 vector_irq 里面。
在系统初始化的时候,我们会调用 __assign_irq_vector,将虚拟中断信号 irq 分配到某个 CPU 上的中断向量。
在这里,一旦找到某个向量,就将 CPU 的此向量对应的向量描述结构 irq_desc,设置为虚拟中断信号 irq 对应的向量描述结构 irq_to_desc(irq)。
这样 do_IRQ 会根据中断向量 vector 得到对应的 irq_desc,然后调用 handle_irq。handle_irq 会调用 generic_handle_irq_desc,里面调用 irq_desc 的 handle_irq。
这里的 handle_irq,最终会调用 __handle_irq_event_percpu。代码如下:
__handle_irq_event_percpu 里面调用了 irq_desc 里每个 hander,这些 hander 是我们在所有 action 列表中注册的,这才是我们设置的那个中断处理函数。如果返回值是 IRQ_HANDLED,就说明处理完毕;如果返回值是 IRQ_WAKE_THREAD 就唤醒线程。
至此,中断的整个过程就结束了。
总结时刻
这一节,我们讲了中断的整个处理过程。中断是从外部设备发起的,会形成外部中断。外部中断会到达中断控制器,中断控制器会发送中断向量 Interrupt Vector 给 CPU。
对于每一个 CPU,都要求有一个 idt_table,里面存放了不同的中断向量的处理函数。中断向量表中已经填好了前 32 位,外加一位 32 位系统调用,其他的都是用于设备中断。
硬件中断的处理函数是 do_IRQ 进行统一处理,在这里会让中断向量,通过 vector_irq 映射为 irq_desc。
irq_desc 是一个用于描述用户注册的中断处理函数的结构,为了能够根据中断向量得到 irq_desc 结构,会把这些结构放在一个基数树里面,方便查找。
irq_desc 里面有一个成员是 irqaction,指向设备驱动程序里面注册的中断处理函数。
课堂练习
你知道如何查看每个 CPU 都收到了哪些中断吗?
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

精选留言(4)
 alexgzh2019-06-15老师, system call, interrup和exception处理的相同点和不同点能讲一下吗?
alexgzh2019-06-15老师, system call, interrup和exception处理的相同点和不同点能讲一下吗? 安排2019-06-12每个CPU的前32个中断也会调用到do_IRQ吗?
安排2019-06-12每个CPU的前32个中断也会调用到do_IRQ吗? 石维康2019-06-12cat /proc/interrupts
石维康2019-06-12cat /proc/interrupts Leon📷2019-06-12中断注册,中断处理,有点类似于rpc框架调用,具体的请求通过事先注册的函数查找,然后返回结果给调用方展开
Leon📷2019-06-12中断注册,中断处理,有点类似于rpc框架调用,具体的请求通过事先注册的函数查找,然后返回结果给调用方展开



